算法架构预备知识信息量熵(Entropy)条件熵信息增益信息增益比基尼指数自助法Bias-Variance Trade-off决策树概述ID3C4.5CART小结集成学习BaggingBoostingAdaboost分类回归BDT分类回归GBDT回归二分类多分类总结Bagging实现随机森林Boosting-GBDT实现XGBoost模型概述原理推导LightGBM参考资料
算法架构
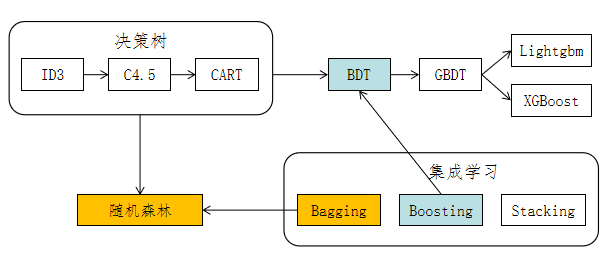
名词解释:
- DT:decision tree,决策树
- BDT:boosting decision tree,集成决策树
- GBDT:gradient boosting decision tree,梯度提升决策树
预备知识
信息量
对某个事件发生概率的度量。一般情况下,概率越低,则事件包含的信息量越大。衡量事件信息量的公式如下:
熵(Entropy)
熵是随机变量不确定性的度量。
设X是一个取值个数为n的离散随机变量,其概率分布为:
则随机变量X的熵定义为:
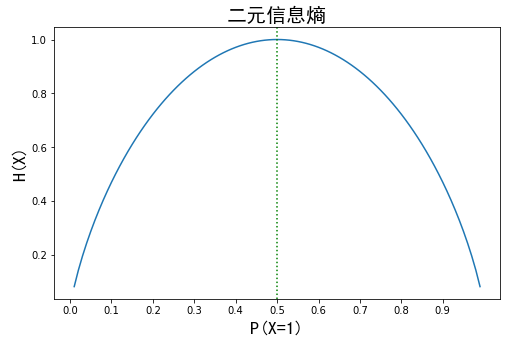
熵越大,随机变量取值的不确定性越大,反之越小。当随机变量的分布为均匀分布时,该随机变量的熵最大。下图为二分类时熵与概率的变化曲线,可以看出,当P(X=1)=0.5时,H(X)最大。
条件熵
表示在已知随机变量X的条件下随机变量Y的不确定性。
设随机变量(X,Y),其联合概率分布为:
给定随机变量X的条件下随机变量Y的条件熵为H(Y|X),定义为X给定条件下Y的条件概率分布的熵对X的数学期望:
信息增益
表示得知特征X的信息从而使得类Y的信息的不确定性减少的程度。
特征A对训练数据集D的信息增益
特征A的取值越多,
信息增益比
特征A对训练数据集D的信息增益比
特征A的取值越多,
基尼指数
分类问题中,假设有K个类,样本点属于第k类的概率为
对于给定的样本集合D,其基尼指数为:
如果样本集合D根据特征A是否取某一可能值a被分割成D1和D2两部分,即:
则在特征A是否取a的条件下,集合D的基尼指数定义为:
Gini(D)表示集合D的不确定性,Gini(D,A)表示将A=a分割后集合D的不确定性。
基尼指数越大,样本集合的不确定性(不纯度)越大,与熵类似。
下式表明基尼指数为熵的一阶泰勒近似值:
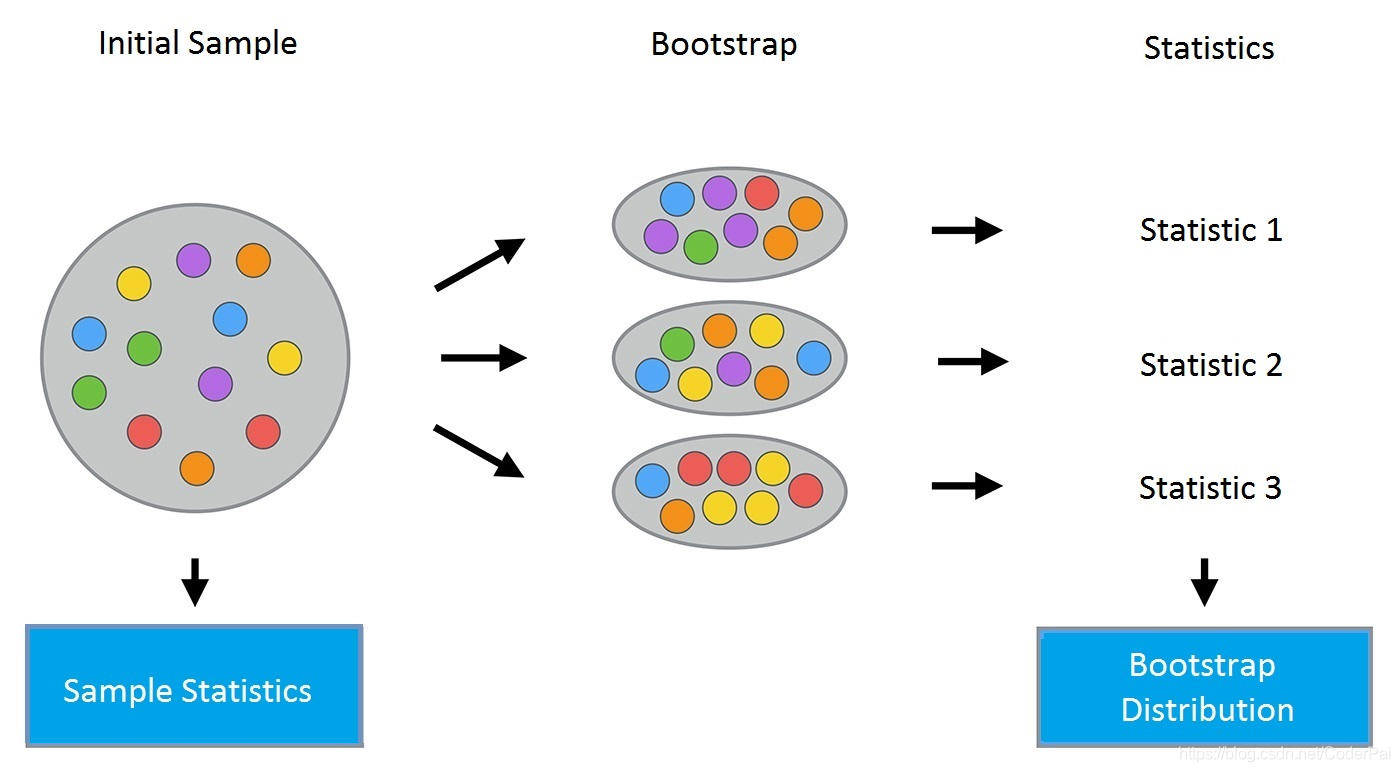
自助法
自助法(bootstrapping)是一种数据采样方法,过程如下:
给定包含m个样本的数据集
将上述过程重复N次,便可以得到N个采样后的样本集。
Bias-Variance Trade-off
| 符号 | 含义 |
|---|---|
| 测试样本 | |
| 数据集 | |
| 基于数据集 | |
| 不同 | |
| 数据集中标记的噪声,等于 |
符号图形化展示如下:
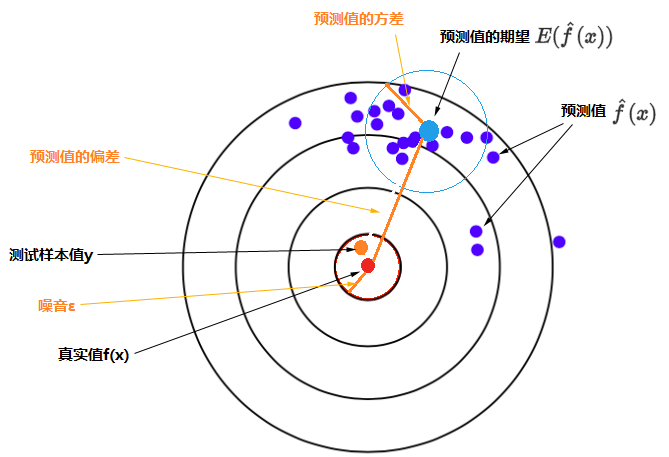
期望预测输出
噪声
数据采集、存储、加工等过程中引入的误差。为便于讨论,假设噪声
噪声用于刻画学习问题本身的难度。
方差
使用样本数相同的不同训练集训练出的模型,对同一
方差用于刻画数据扰动对模型的影响,即不同训练数据集训练出的不同模型对同一个待预测
偏差
期望输出(所有可能的训练数据集训练出的所有模型的输出的平均值)与真实标记的差别称为偏差(bias),即:
偏差用于刻画学习算法本身的拟合能力。
- 期望泛化误差
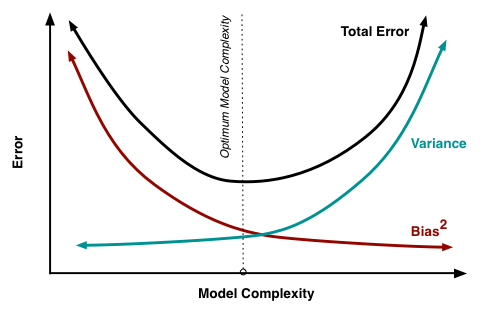
偏差-方差分解说明,泛华性能由学习算法的能力、数据的充分性以及学习任务本身的难度共同决定。
直观展示
下图将机器学习任务描述为一个「打靶」的活动:根据相同算法、不同数据集训练出的模型,对同一个样本进行预测;每个模型作出的预测相当于是一次打靶。
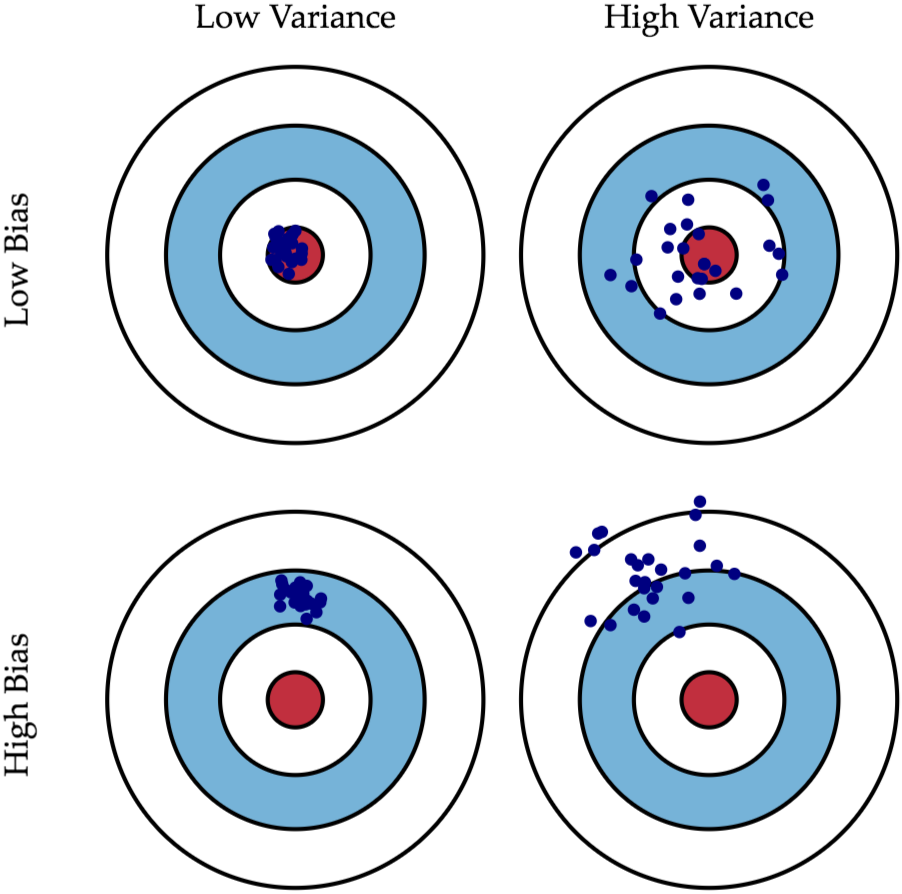
- 左上角:低偏差,低方差。如果有无穷的训练数据,以及完美的模型算法,有希望达成这样的情况。然而,现实中的工程问题,通常数据量是有限的,而模型也是不完美的。因此,这只是一个理想状况。
- 右上角:低偏差,高方差。靶纸上的落点都集中分布在红心周围,它们的期望落在红心之内,因此偏差较小。另外一方面,落点虽然集中在红心周围,但是比较分散,这是方差大的表现。
- 左下角:高偏差,低方差。靶纸上的落点非常集中,说明方差小。但是落点集中的位置距离红心很远,这是偏差大的表现。
- 右下角:高偏差,高方差。最差的情况。
总结
- 泛化误差由偏差、方差、噪声构成。
- 模型训练的起始阶段,拟合效果差,偏差较大,数据集的变化对于模型的影响也很小,因此方差较小。此时模型表现为欠拟合。
- 随着训练得深入,模型的拟合能力越来越强,偏差逐渐减小,方差逐渐增大。
- 当模型训练到一定程度时,它的拟合能力非常强,这时所有样本都可以很好地被拟合,偏差很小,但是训练集细微的变化都会对模型的效果产生很大的影响,方差很大,将发生过拟合。
决策树
概述
决策树是一种基本的分类与回归方法,它可以认为是一种if-then规则的集合。决策树由节点和有向边组成,内部节点代表特征,叶子节点代表类别。
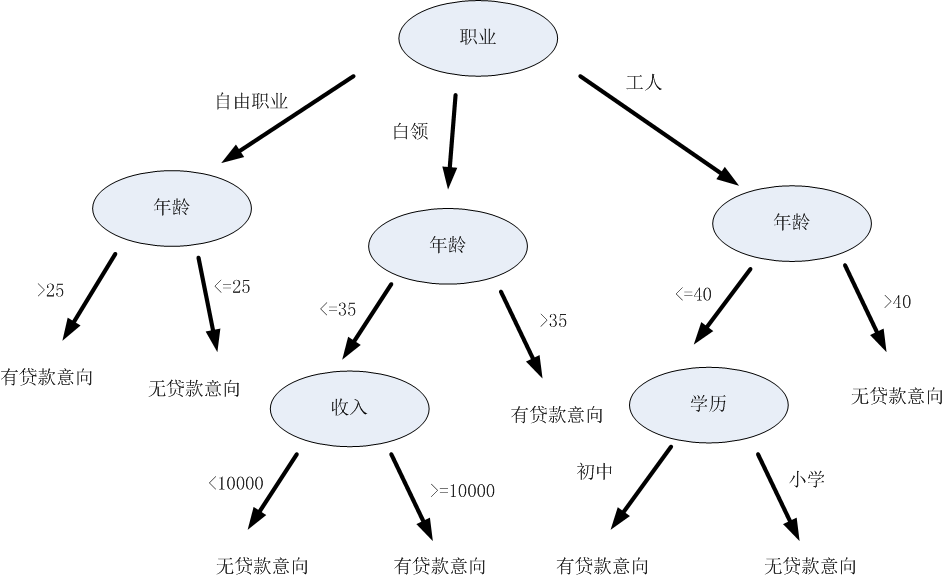
下图为决策树的一个图例,判断用户是否有贷款意向:
决策树递归地选择特征并对整个特征空间进行划分,从而对样本进行分类,其过程如下所示:
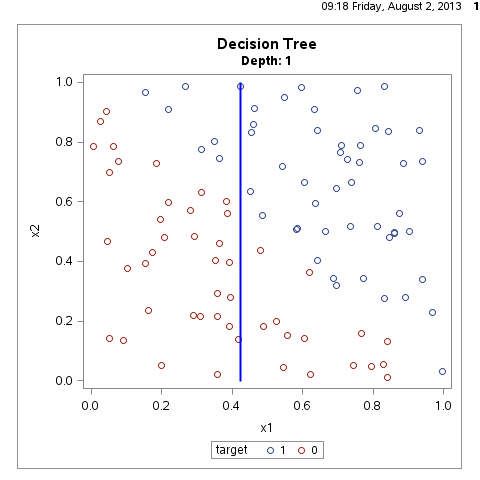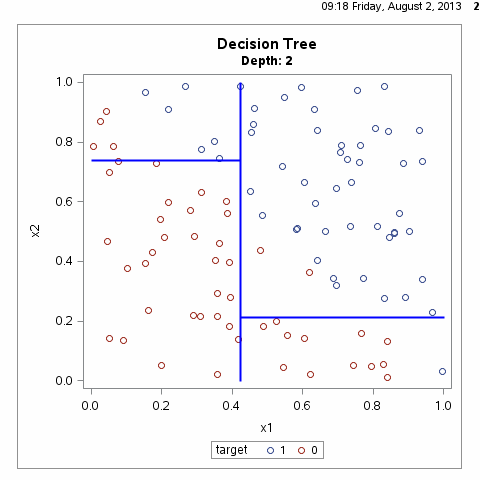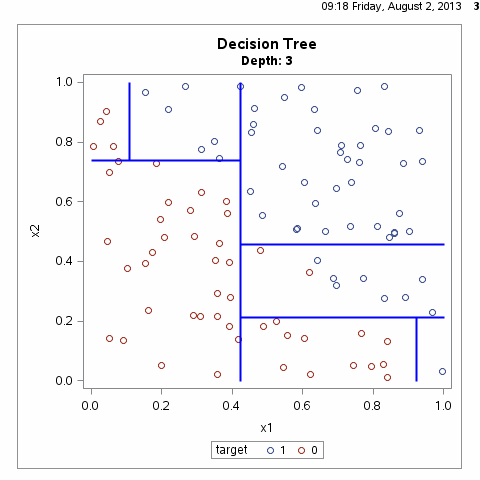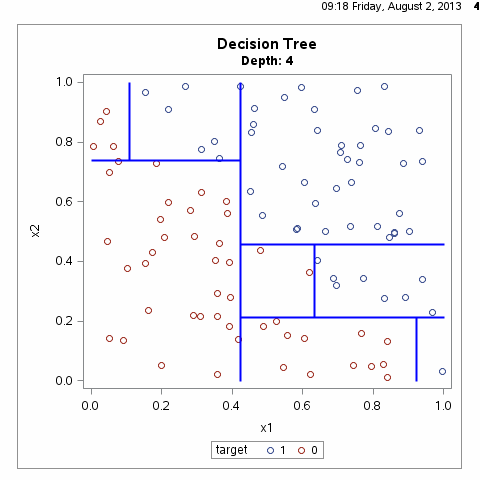
从上图可以看出,决策树划分的方式有无数种,如何得到最优的决策树?即对训练数据有较好分类效果,同时对测试数据有较低的误差率。
根据特征选择依据的不同,决策树有三种生成算法,包括:ID3、C4.5、CART(Classification and Regression Tree)。
ID3
一、特征选择依据:选择信息增益最大的特征。
二、构建过程:
输入:训练数据集D,特征集A,阈值
输出:决策树T
主要过程:
1、计算A中各特征对D的信息增益,即G(D, A),选择信息增益最大的特征
2、若
3、对
4、对第i个子节点,以
三、优点
1、构建决策树的速度比较快,算法实现简单,生成的规则容易理解。
四、缺点
1、倾向选择取值较多的特征。
2、只能处理离散特征,不能处理连续特征。
3、无修剪过程。
C4.5
一、特征选择依据:选择信息增益比最大的特征。
二、构建过程
输入:训练数据集D,特征集A,阈值
输出:决策树T
主要过程:
1、计算特征A中各特征对D的信息增益比,即
2、若
3、对
4、对第i个子节点,以
三、优点
1、能够处理缺失值
a、计算信息增益比时缺失:忽略;将此属性出现频率最高的值赋予该样本。
b、按该属性创建分支时缺失:忽略;将此属性出行频率最高的值赋予该样本;为缺失值创建一个分支。
c、预测时,待分类样本的属性缺失:到达该属性时结束,将该属性所对应子树中概率最大的类别作为预
测类别;将此属性出行频率最高的值赋予该样本,然后继续预测。
2、能够处理离散值和连续值(按属性值排序,按二分法枚举两两属性值之间的阈值点进行离散化)。
3、构造树有后有剪枝操作,防止过拟合。
四、缺点
1、倾向选择取值较少的特征。
2、针对连续值特征,计算效率低。
CART
一、特征选择依据:选择基尼指数最小的特征。
二、构建过程 - 回归树
输入:训练数据集D
输出:回归树f(x)
主要过程:
1、遍历特征
2、用选定的
3、继续对两个子区域调用步骤1~2,直到满足停止条件。
4、将输入空间划分为
三、构建过程 - 分类树
输入:训练数据集D,停止计算的条件
输出:CART决策树
主要过程:
1、对训练数据集D,对每个特征A,对A可能取的每个值a,根据对
2、对所有可能的特征及其取值,选择基尼指数最小的特征及其取值,作为最优特征及最优切分点。根据最优特征及最优切分点,从现节点生成两个子节点,将训练数据集依特征分配到两个子节点中去。
3、继续对两个子区域调用步骤1~2,直到满足停止条件。
4、生成CART决策树。
小结
| 算法 | 场景 | 树结构 | 特征选择 | 连续值 | 缺失值 | 剪枝 |
|---|---|---|---|---|---|---|
| ID3 | 分类 | 多叉树 | 信息增益 | 不支持 | 不支持 | 不支持 |
| C4.5 | 分类 | 多叉树 | 信息增益比 | 支持 | 支持 | 支持 |
| CART | 分类,回归 | 二叉树 | 基尼指数,MSE | 支持 | 支持 | 支持 |
集成学习
集成学习是通过训练若干个弱学习器,通过一定的组合策略,从而形成一个强学习器。按照基学习器之间是否存在依赖关系,可以分为两类:
- 基学习器之间不存在强依赖关系:基学习器可以并行生成,代表算法是bagging系列算法。
- 基学习器存在强依赖关系:基学习器需要串行生成,代表算法是boosting系列算法。
Bagging
Bagging(bootstrap aggregating)是并行式集成学习方法的代表。
以分类为例,假设训练集为X,利用自助法,可以生成N个样本集
算法流程如下:
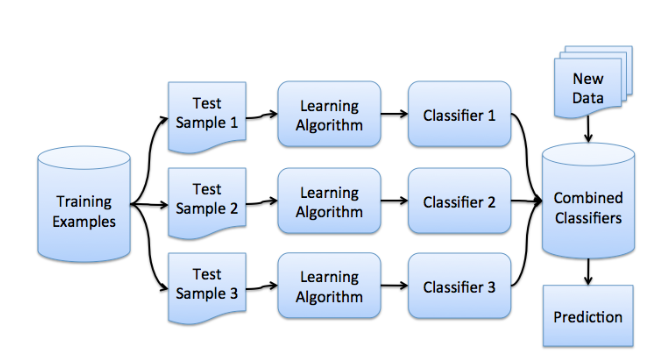
假设N个模型预测的结果分别为
说明bagging模型预测的期望近似于单模型的期望,意味着bagging模型的bias与单模型的bias近似,所以bagging通常选择偏差低的强学习器。
bagging的抽样是有放回抽样,因此数据集之间会有重复的样本,模型的预测结果不独立。假设单模型之间具有一定相关性,相关系数为
所以,当N较大时,
Boosting
Adaboost
需要解决的两个问题:
每一轮如何改变训练数据的权值或概率分布?
提高前一轮被错误分类的样本的权值,降低被正确分类的样本的权值。
如何将弱分类器组合成一个强分类器?
加权多数表决。加大误差率低的分类器的权值,较小误差率高的分类器的权值。
分类
输入:训练数据集
输出:最终分类器
算法步骤如下:
初始化训练数据的权值分布(该值影响分类误差率)
对
- 使用具有权值分布
计算分类误差率
计算
计算弱分类器
更新训练数据集的权值分布
其中,
由上式可知,规范化后使得
构建弱分类器的线性组合
最终分类器
回归
输入:训练数据集
输出:最终分类器
算法步骤如下:
初始化训练数据的权值分布(该值影响分类误差率)
对迭代次数
使用具有权值分布
计算训练集上的最大误差
计算单个样本的相对误差
计算弱分类器
计算弱分类器的系数
更新训练数据集的权值分布
其中,
由上式可知,规范化后使得
构建弱分类器的线性组合,得到最终的强学习器
BDT
BDT(boosting decision tree),提升决策树。
分类
将Adaboost分类算法中的基本分类器限定为二分类树模型即可。
回归
输入:训练数据集
输出:提升树
算法步骤:
定义模型
其中,参数
定义损失函数
损失函数使用MSE,因此,第
因此,对回归提升树来讲,只需拟合当前模型的残差即可。
对
计算残差:
生成第
根据
更新模型
生成最终的回归问题提升树
GBDT
GBDT(gradient boosting decision tree),梯度提升决策树。
回归
以回归为例,解释GBDT原理。
解释一
对回归问题,给定输入
根据boosting算法:
在给定已知模型
根据泰勒展开公式:
对
由于
根据向量点乘定义,当
在每轮迭代中,
解释二
从函数空间考虑,为了使得
而根据加法模型:
为了使得
二分类
对二分类问题,可以使用0和1表示预测类别。预测值的区间为
定义模型
对二分类问题,给定输入
模型初始化为:
定义损失函数
损失函数使用交叉熵损失,即:
求负梯度
因为GBDT拟合的是损失函数关于模型的负梯度,求导可得:
所以,在第m轮,
迭代,对
对
计算负梯度,
拟合回归树,生成第m棵回归树
对
对于
由于上式没有闭式解,所以采用近似值代替,代替过程如下:
更新强学习器
生成最终强学习器
结果预测
多分类
假设有K个类别,对类别进行one-hot处理后,样本集形式为
模型最终生成K棵集成决策树。
定义模型
给定输入x,属于第k类的概率为:
对
定义损失函数
求损失函数关于
因此,第m轮第i个样本对应的第q个类别的损失函数负梯度为:
迭代,对
对
计算损失函数的负梯度:
对
对于
更新强学习器
生成最终强学习器
结果预测
总结
| 集成方法 | 优点 | 缺点 | 示例 |
|---|---|---|---|
| bagging | 能处理过拟合; 能够降低variance; 学习器独立,可并行训练; | 噪声大时会过拟合; 可能会有很多相似的决策树; 小数据或低维数据效果一般; | 随机森林 |
| boosting | 能够降低bias和variance; | 容易过拟合; 串行训练; | GBDT |
Bagging实现
随机森林
假设数据样本数为N,每个样本的属性个数为M,在每个决策树构造过程中,每个节点随机选择m个属性计算最佳分裂方式进行分裂。具体步骤如下:
- 有放回地随机选择N个样本,用这N个样本来训练一棵决策树。
- 每个样本有M个属性,在决策树中需要分裂节点时,从这M个属性中随机选取m个属性,一般来说m << M,然后从这m个属性中采用某种策略选择最佳属性作为当前节点的分裂属性。
- 每棵决策树的每个节点的分裂都按照步骤(2)进行,直到不能分裂为止。
- 重复建立K棵决策树,然后对预测结果进行一定组合,即可得随机森林模型。
Boosting-GBDT实现
XGBoost
模型概述
原理推导
输入:训练数据集
输出:提升决策树模型,由
- 定义模型
决策树定义为:
其中,
决策树结构图如下所示:
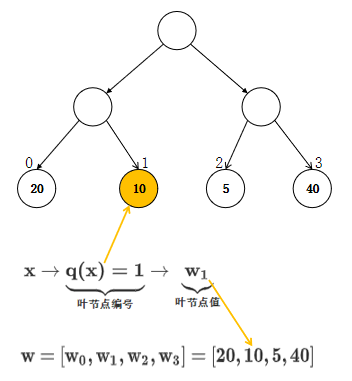
- 定义损失函数
第
第
第
定义叶结点
由于:
可令:
得到每个叶结点
代入每个叶结点
- 节点分裂准则
假设
使用
- XGBoost 节点分裂贪婪查找算法
算法说明:枚举所有特征,对每个特征,枚举每个分裂点,根据
输入:当前节点实例集
输出:根据最大score分裂
算法步骤:
for
for
LightGBM
- 分裂准则:
基于决策树某节点的数据集
特征
解释一:基于CART树寻找最优分裂点
解释二:参考XGBoost的信息增益
因为使用的是平方损失,那么样本的二阶导数为1,即
GOSS(Gradient based One Side Sampling) - 样本下采样
选择前
从剩余的
对小梯度样本, 在计算信息增益时扩大一定倍数
由于梯度较大的数据实例在信息增益的计算中起着更重要的作用,所以GOSS可以在较小的数据量下获得相 当准确的信息增益估计。
EFB(Exclusive Feature Bundling) - 独立特征合并
解决数据稀疏的问题。在稀疏特征空间中,许多特征都是互斥的,也就是它们几乎不同时取非0值。因此,可以安全地把这些互斥特征绑到一起形成一个特征。
参考资料
- https://statisticallearning.org/biasvariance-tradeoff.html
- https://www.cs.cornell.edu/courses/cs4780/2018fa/lectures/lecturenote12.html
- https://bcheggeseth.github.io/CorrelatedData/index.html
- http://www.milefoot.com/math/stat/rv-sums.htm
- https://stats.stackexchange.com/questions/391740/variance-of-average-of-n-correlated-random-variables
- https://github.com/Freemanzxp/GBDT_Simple_Tutorial
- https://scikit-learn.org/stable/modules/ensemble.html
- https://scikit-learn.org/stable/modules/tree.html#tree-algorithms-id3-c4-5-c5-0-and-cart