感知机2021-09-11
感知机模型简介
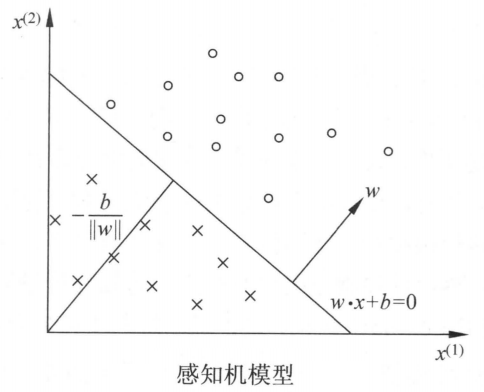
感知机(perceptron)是二分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,取值为。感知机对应于输入空间(特征空间)中将实例划分为正负两类的分离超平面,属于判别模型。
定义 (感知机) 假设输入空间(特征空间 ) 是 , 输出空间是 。 输入 表示实例的特征向量, 对应于输入空间 (特征空间 ) 的点; 输出 表示实例的类别。由输入空间到输出空间的如下函数称为感知机:
其中, 和 为感知机模型参数, 叫作权值 ( weight ) 或权值向 量( weight vector ), 叫作偏置 ( bias ) , 表示 和 的内积。 是符号函数, 即
感知机学习策略
空间中任意一点到超平面的距离:
对误分类的数据来说:
因此,误分类点到超平面的距离是:
假设超平面的误分类点集合为,那么所有误分类点到超平面的总距离为:
根据以上推导,可得出感知机的损失函数:
给定训练数据集 ,其中,。感知机学习的损失函数定义为:
感知机学习算法
原始形式
优化目标:
采用梯度下降法进行优化,损失函数的梯度为:
随机选取一个误分类点,对进行更新:
对偶形式
基本想法是:将和表示为实例和标记的线性组合的形式,通过求解其系数而求得和。不失一般性,在中可假设初始值均为0。对分类点通过
逐步修改。
设修改次,则关于的增量分别是和,这里。从学习过程中不难看出,最后学习到的可以分别表示为:
其中,,当时,表示第个实例点由于误分类而进行更新的次数。
。
对偶形式中训练实例仅以内积的形式出现。为了方便,可以预先将训练集中实例间的内积计算出来并以矩阵的形式存储,该矩阵称为Gram矩阵: