Voting
针对分类问题,多个模型投票,少数服从多数,得到最终的预测结果。
选择模型时,要求模型是弱相关性的。
Averaging
针对回归问题,多个模型求(加权)均值,模型系数可以通过网格搜索获取。
Stacking与Blending
二者本质相同,混叫。
整体架构如下:
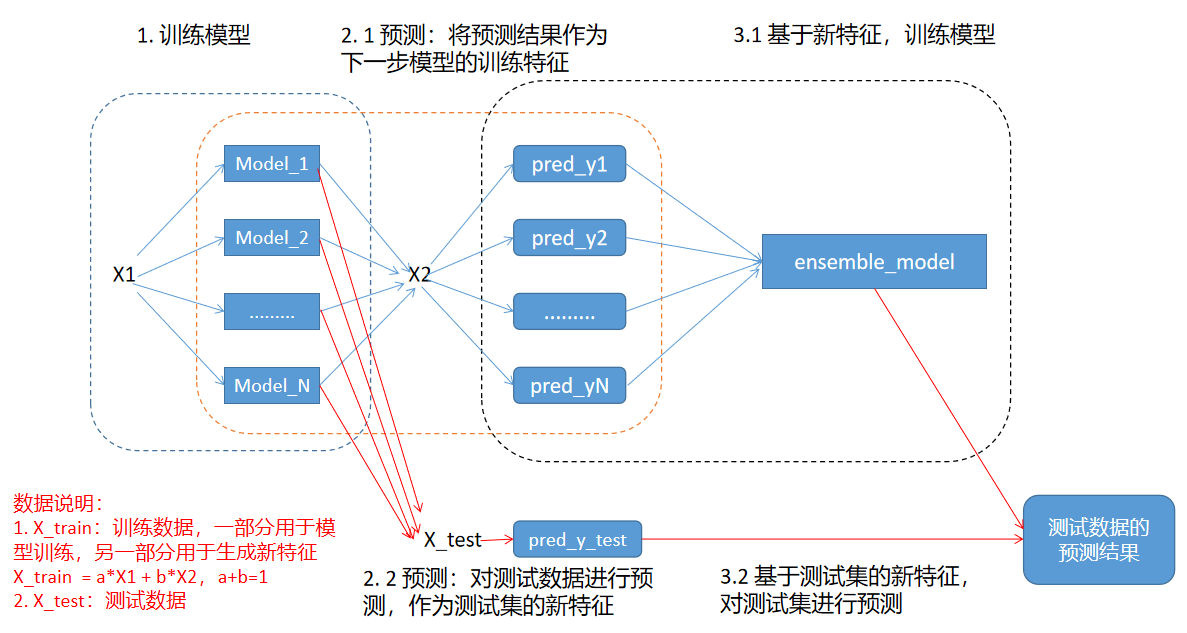
Stacking
其本质是使用模型对数据特征进行编码,从而得到新的特征,基于新特征,再训练模型进行最终预测。
生成新特征
对训练数据,使用交叉验证训练模型,每一折都将得到预测结果,将所有预测结果合并起来,即为整个训练数据集的预测结果。对该预测结果,换一个角度,可以看成是新的特征数据。假设有
对测试数据,每一折都会对全量数据进行预测,可以采用取平均的方式得到对应的全量测试数据的预测结果。
下图为1个模型得到的新特征数据:
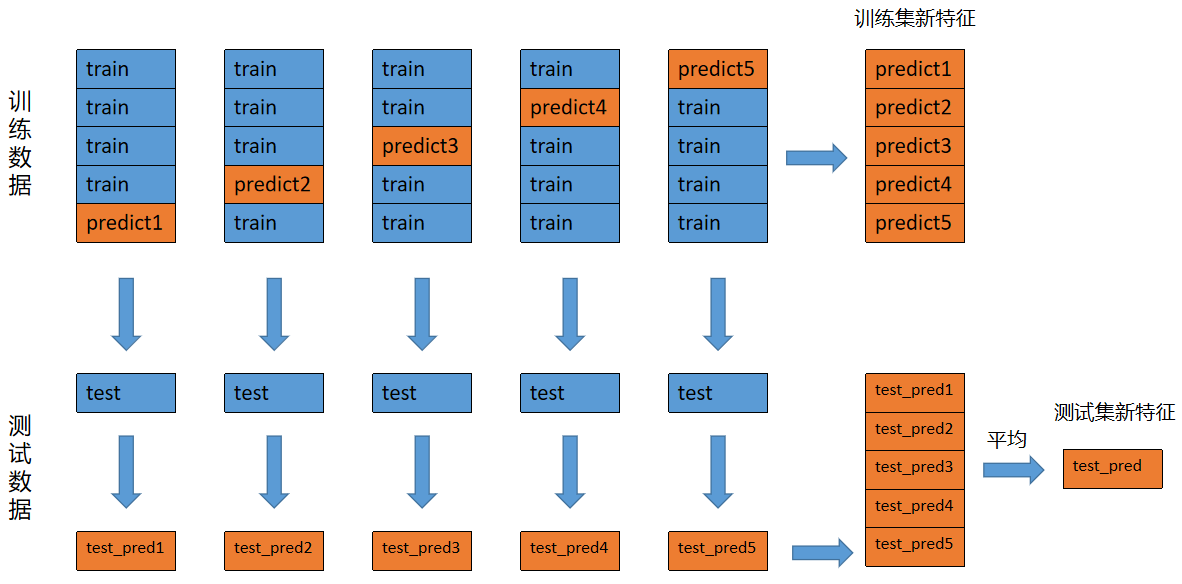
预测
基于新的特征,训练新的模型,然后对新测试数据特征进行预测,得到最终的预测结果。
下图展示的是整体Stacking过程:经过LR、RF、GBDT共3个模型生成新特征数据,然后再训练XGB模型并进行预测。
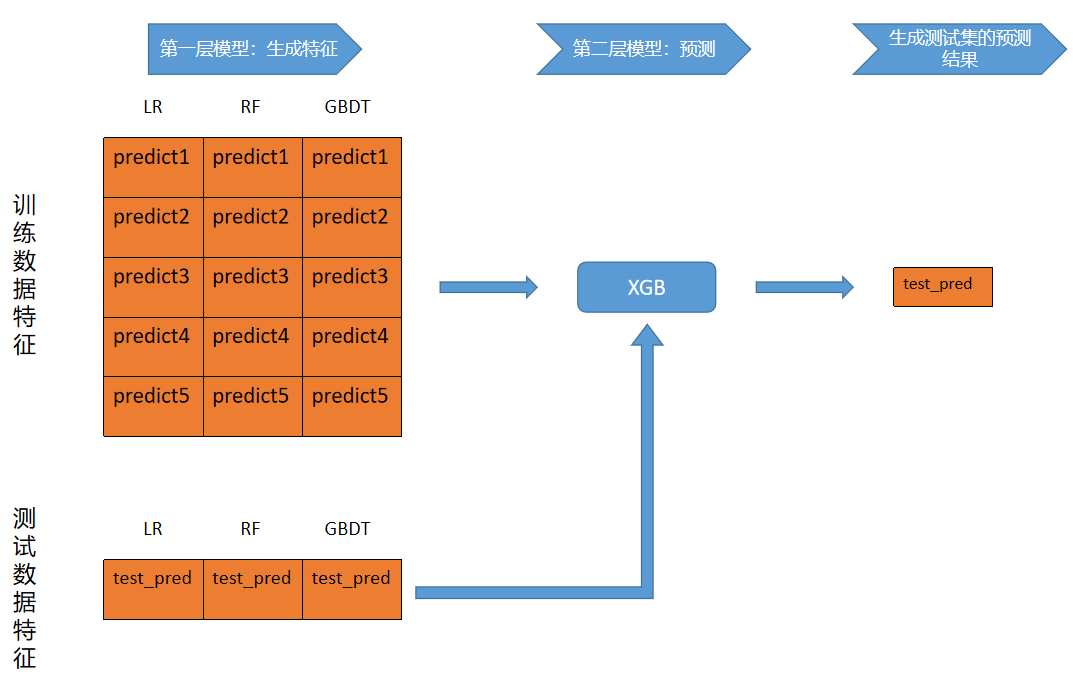
Blending
非交叉堆叠。整体做法和Stacking类似,不同之处是Blending不做交叉验证,在第一层模型训练时,将训练数据按照一定比例切分,比如7:3,70%的数据用作训练,30%的数据用作验证,然后将验证结果作为第二层模型的训练特征。
AdaBoost
由 Yoav Freund 和 Robert Schapire 提出,两人因此获得了哥德尔奖。
基本原理
模型集成的一种宏方法,目的是将若干个弱学习器组合为一个强学习器,核心是如何计算样本权重和学习器权重:
串行训练弱学习器;
权重调整
- 调整弱学习器权重:根据弱学习的分类误差率调整该学习器的权重;
- 调整样本权重:每一轮训练完成后,根据当前弱学习器的分类结果调整样本的权重,即训练正确的样本降低权重,训练错误的样本提高权重;
将若学习器组合为强学习器。
实现步骤
首先,定义如下符号:
下图为AdaBoost的过程图例(分类问题):
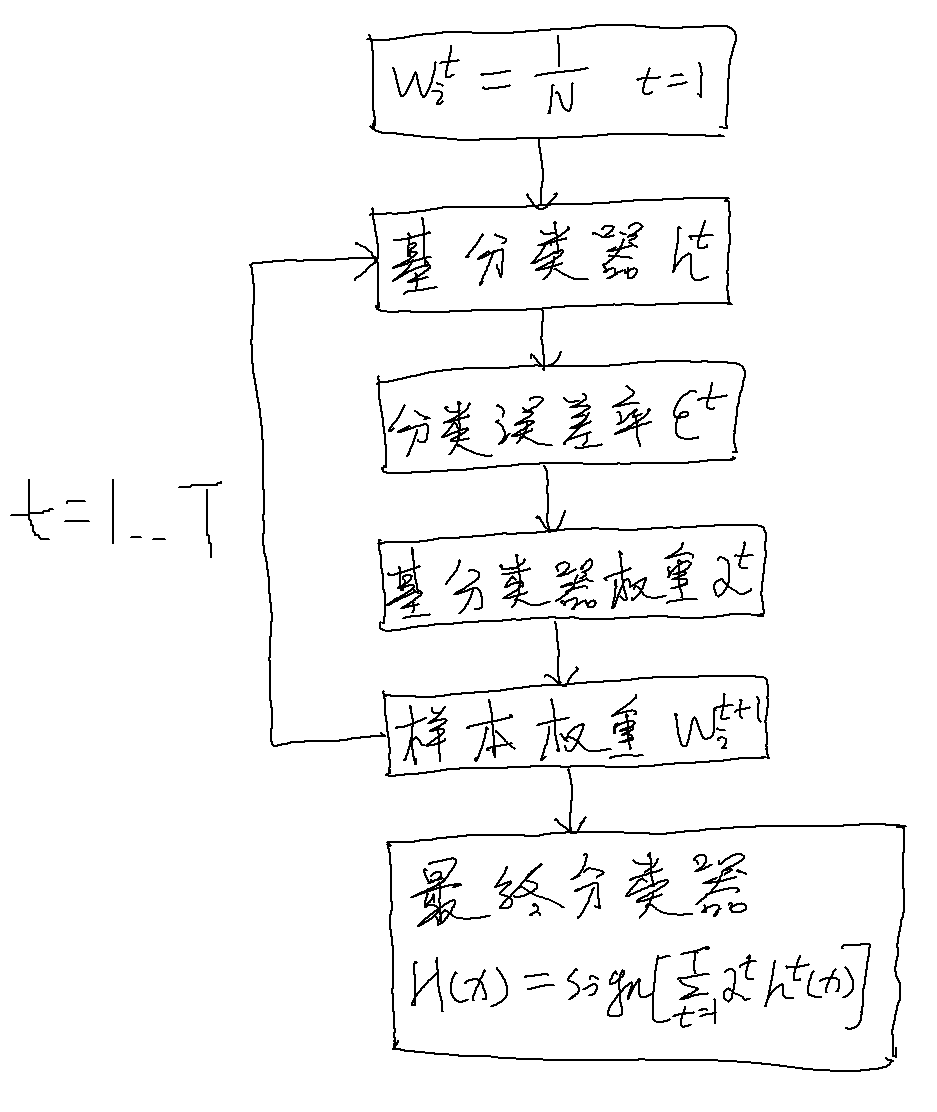
接下来,以二分类问题(
初始化训练数据的权值分布
对
基于当前的权值分布
计算
由上式可知,分类误差率等于预测错误样本的权重。
计算若学习器
更新训练数据的权值分布
构建弱分类器的线性组合
得到最终的分类器:
公式简化
简化归一化因子
简化样本权重
有意思的事情
对于预测正确的样本,其更新后的样本权重之和为0.5:
对于预测错误的样本,结论一样。