数据集
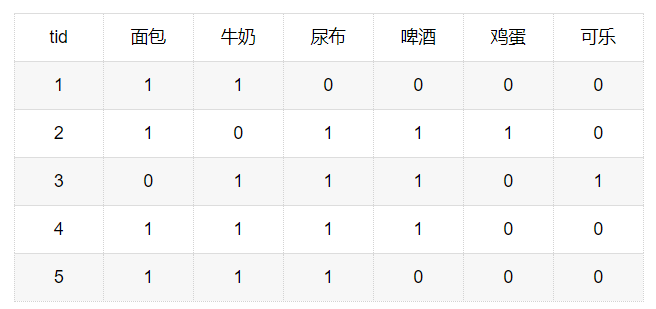
基本概念
项集
购买商品的集合。
频繁项集
经常出现在一起的商品的集合。
关联规则
关联规则是形如
评估指标
支持度
项集
例如,
置信度
在项集
例如,
提升度
项集
例如,
Apriori
对于Apriori算法,通常使用支持度作为判断频繁项集的标准,Apriori算法的目标是找到最大的K项频繁集。
Apriori采用迭代的方法寻找最大的K项频繁集。具体如下:
- 搜索出候选1项集及对应的支持度,剪枝去掉低于支持度阈值的1项集,得到频繁1项集;
- 对剩下的频繁1项集进行连接,得到候选的频繁2项集,筛选去掉低于支持度的候选频繁2项集,得到真正的频繁2项集;
- 依次类推,迭代下去,直到无法找到频繁K+1项集为止,对应的频繁K项集的集合即为算法的输出结果。
下图为Apriori算法过程示例:
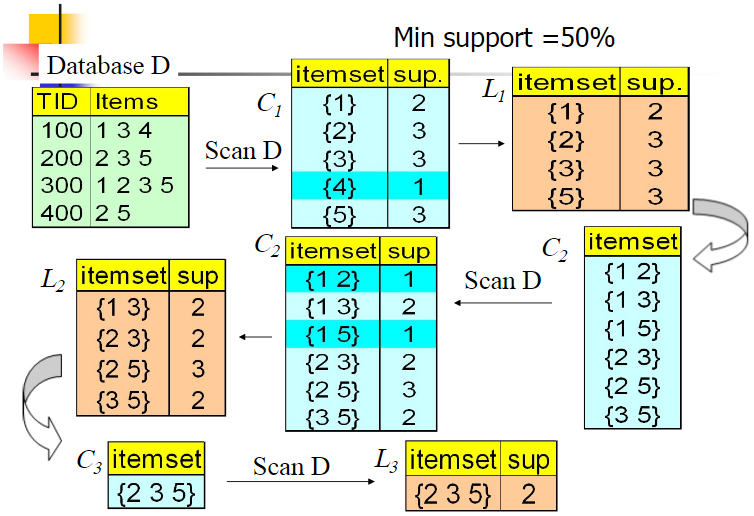
在该例中,共有4条记录:134、235、1235、25。使用Apriori算法寻找频繁K项集,设最小支持度为0.5。步骤如下:
- 生成候选频繁1项集,然后计算支持度
- 基于
- 基于
- 由于无法再进行连接得到频繁4项集,最终的结果即为频繁3项集235
参考文档
- Apriori算法原理总结 - 刘建平Pinard - 博客园 (cnblogs.com)
- 实战:关联规则挖掘 - 知乎 (zhihu.com)
- 第一部分 关联规则实战分析 1-关联规则概述哔哩哔哩bilibili