GBDT+LR模型简介
简而言之,GBDT+LR是特征工程模型化的开端。
此时的GBDT,不是用来做预测,而是基于原始特征生成新的特征。
LR模型简单,能够处理海量的数据,但是依赖于人工做特征工程。
GBDT是由多颗回归树组成的树模型,后一棵树将前面树模型预测的结果与真实结果的残差为拟合目标。每棵树生成的过程是一颗标准的回归树生成过程,因此回归树中每个节点的分裂是一个自然的特征选择过程,而多层节点的结构则对特征进行了有效的自动组合,也就非常高效地解决了特征选择和特征组合的问题。
因此,使用GBDT对训练数据进行特征选择与特征组合,然后将其结果作为特征加入到训练数据,再使用LR模型进行预测。
GBDT生成特征过程
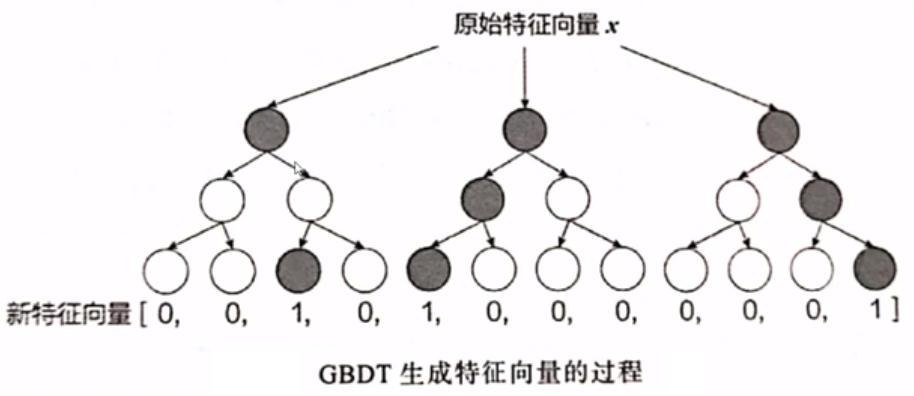
假设GBDT由3颗决策树组成。对当前的特征数据
| 决策树 | 映射结点 | one-hot编码 |
|---|---|---|
| 第1颗树 | 3 | [0,0,1,0] |
| 第2颗树 | 1 | [1,0,0,0] |
| 第3颗树 | 4 | [0,0,0,1] |
将上述的one-hot编码进行合并,可得向量:[0,0,1,0,1,0,0,0,0,0,0,1],定义该向量为gbdt_feat。此过程也可以理解为使用GBDT模型对数据进行了Embedding。
将该向量与原始的特征数据进行合并,即可得到新的特征数据:
接下来,将
GBDT+LR模型训练过程
假设训练的原始数据为
GBDT生成特征
- 对
- 使用
- 使用GBDT模型对
- 将index进行one-hot编码处理,合并后,得到
LR模型训练
- 构建新的训练数据:
- 对
- 将
示例代码
参考文档
- predicting-clicks-facebook.pdf (quinonero.net)
- 2.2.1 GBDT+LR (datawhalechina.github.io)
- zhongqiangwu960812/AI-RecommenderSystem: 该仓库尝试整理推荐系统领域的一些经典算法模型 (github.com)