Attention 架构
Luong Attention分为Local和Global两种,本文主要分析Global Attention。下图为Global Attention的架构图:
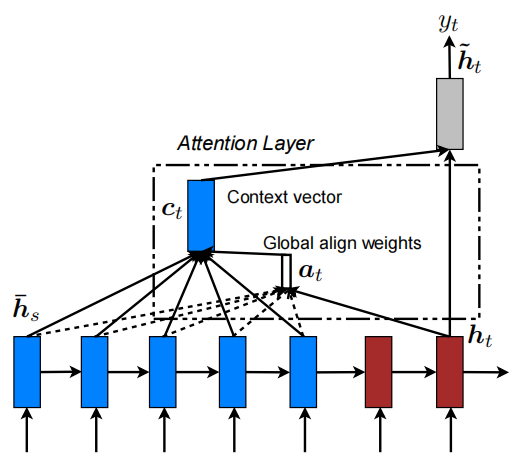
符号解释:
以中英文翻译场景为例,根据该架构图,分为如下计算步骤:
attn_weights计算
通过encoder_output和decoder_output计算得到attn_weights,即
Context vector计算
通过encoder_output和
attentional hidden state计算
将
预测
根据
Attention计算流程
Global Attention计算流程如下图所示:
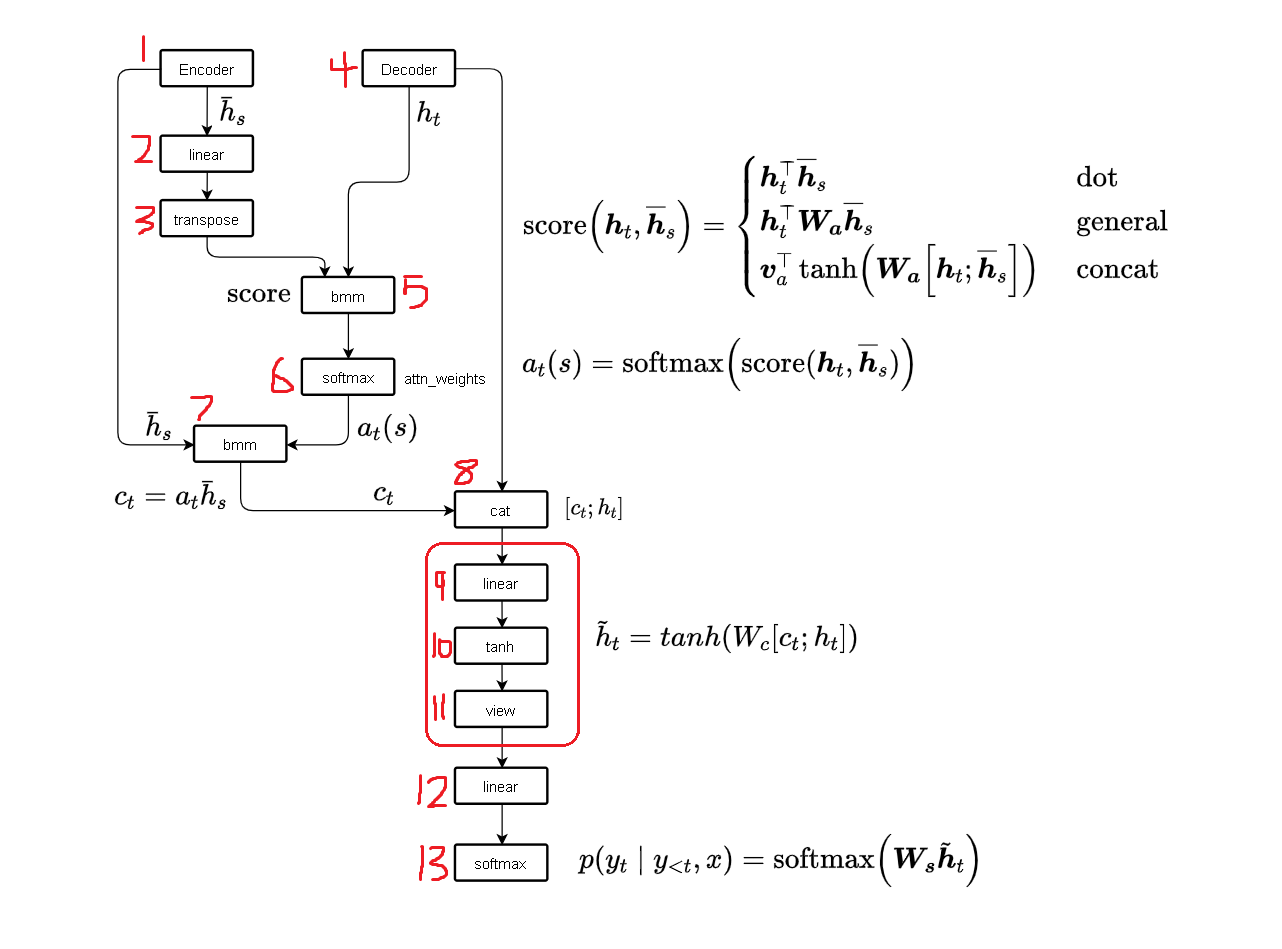
计算步骤如下:
Encoder
step1:对原始输入,通过
step2:为了能够使得encoder_output和decoder_output做
step3:transpose(1,2)
Decoder
RNN
step4:对Decoder端的输入,通过
Attention
step5:基于
step6: 对打分结果通过
step7: 基于
Attentional hidden state
step8:将加权encoder_output通过
为了方面后续的
step9:对
step10:
step11:将二维展开到三维,得到最终的attentional hidden state
Predict
step12:对
step13:通过