总体架构输入EncoderDecoder 模型须知模型参数输入与输出注意Encoder输入Input EmbeddingPositional Encoding输入整合AttentionSelf-AttentionMulti-head Attentionaddnorm线性层Feed ForwardaddnormEncoder block总结Decoder输入Output EmbeddingPositional Encoding输入整合Masked AttentionMasked Multi-Head AttentionMulti-Head Attention线性层结果输出LinearSoftmaxLoss预测参考文档
总体架构
模型分为Encoder和Decoder两个部分,下图为模型的架构图:
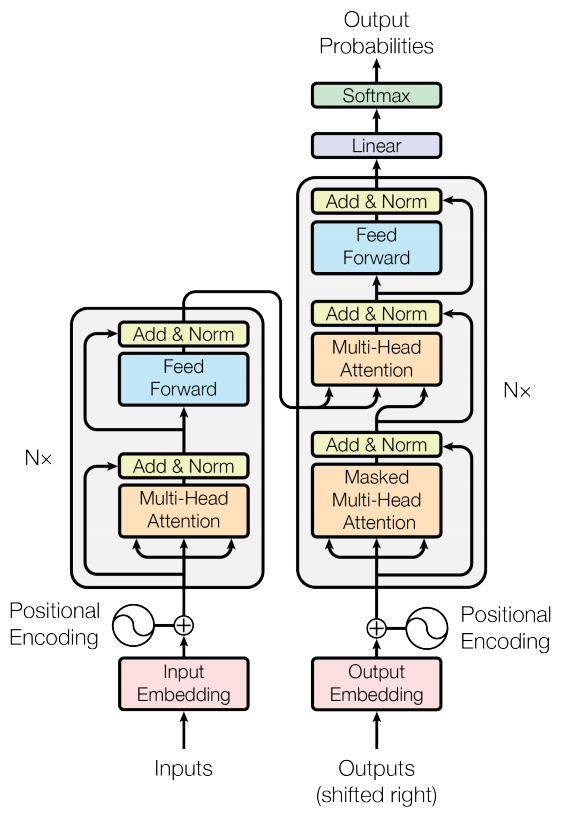
下面,以翻译为例,介绍Transformer的工作过程:
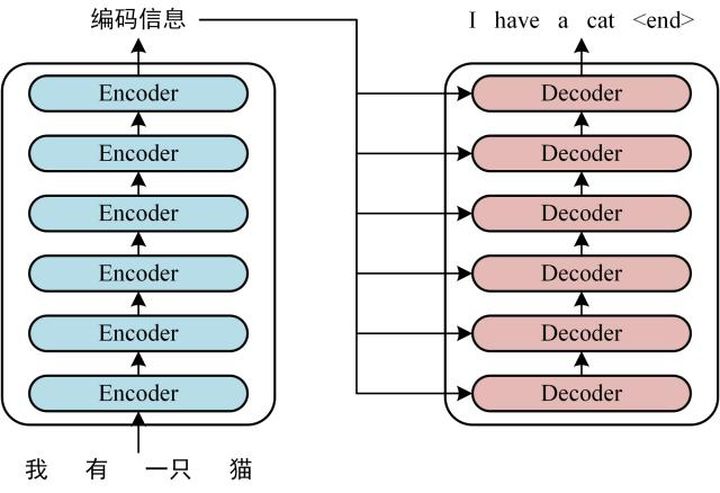
输入
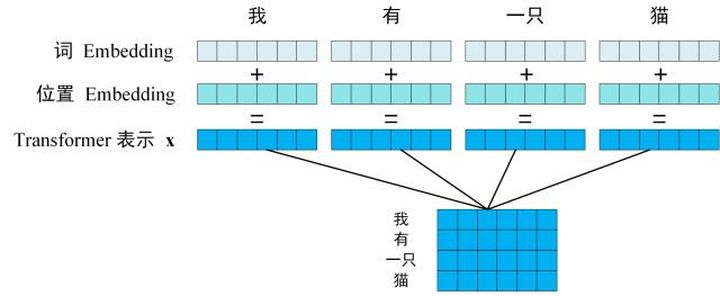
通过Input Embedding和Positional Encoding,将句子表示为编码,记为
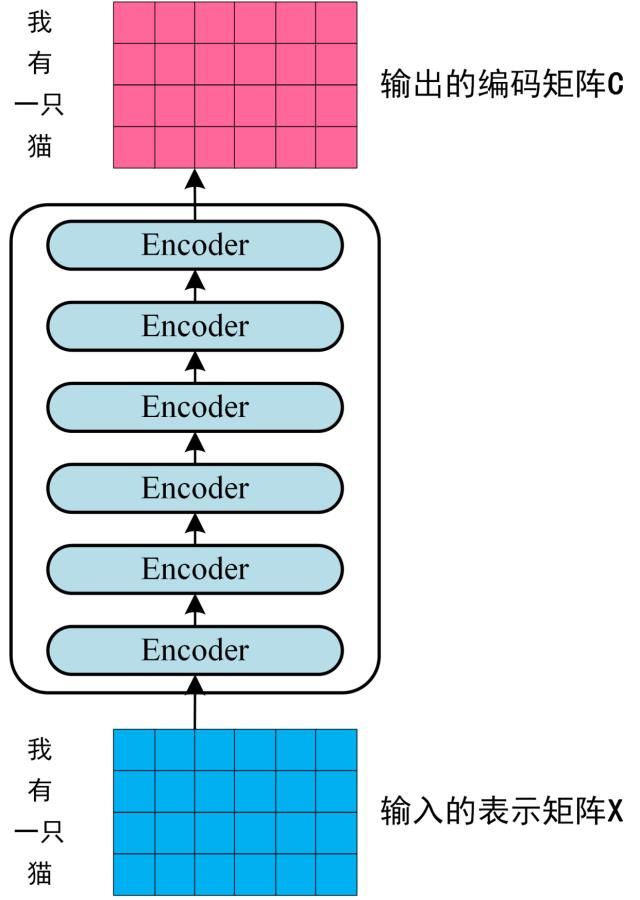
Encoder
对
Decoder
将Encoder输出的编码信息矩阵
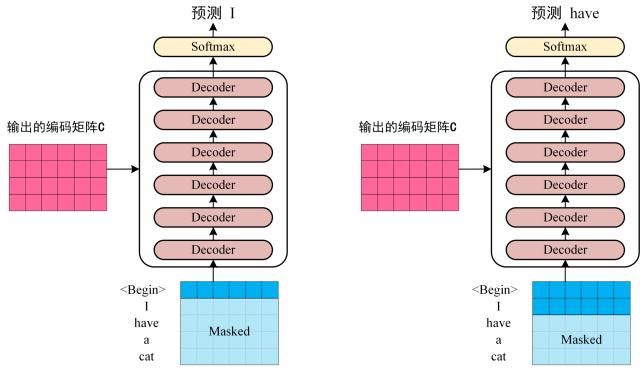
模型须知
模型参数
batch_size
批量大小
src_len
Encoder端句子的最大长度
tgt_len
Decoder端句子的最大长度
d_model
词的Embedding Size
d_k (d_q)
矩阵Q、K的列数
d_v
矩阵V的列数
d_ff
Feed Forward的隐藏层个数
src_vocab_size
源端单词个数
tgt_vocab_size
目标端单词个数
输入与输出
1enc_input dec_input dec_output2['我 是 中国人 P', 'S i am chinese P', 'i am chinese P E'],3['我 有 一只 猫' , 'S i have a cat', 'i have a cat E']
enc_input
encoder input
dec_input
decoder input
dec_output
decoder output,相当于y_true
注意
对于变量符号,为了方便起见,有重名的情况。比如在Encoder和Decoder中,Attention都有可能使用
Encoder
输入
Input Embedding
使用word2vec,对
Positional Encoding
因此,Positional Encoding结果的shape为[batch_size, src_len, d_model]。
记Positional Encoding的结果为
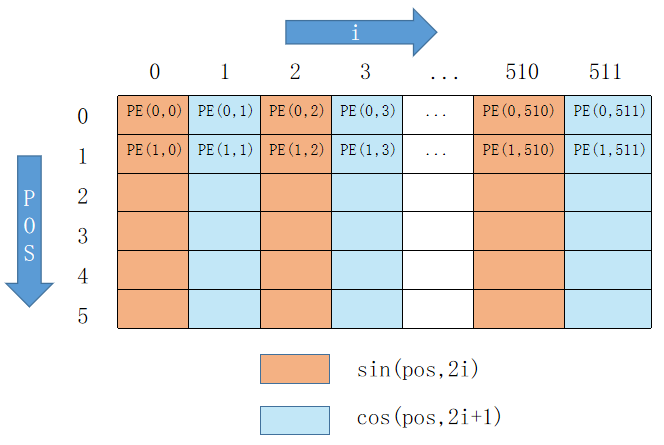
输入整合
shape为[batch_size, src_len, d_model]。
Attention
Encoder的Multi-Head Attention由多个Self-Attention组成,Self-Attention接收的是输入(单词的表示向量x组成的矩阵X)或者上一个Encoder block的输出,下面将对Self-Attention进行介绍。
Self-Attention
序列
整体计算流程如下:
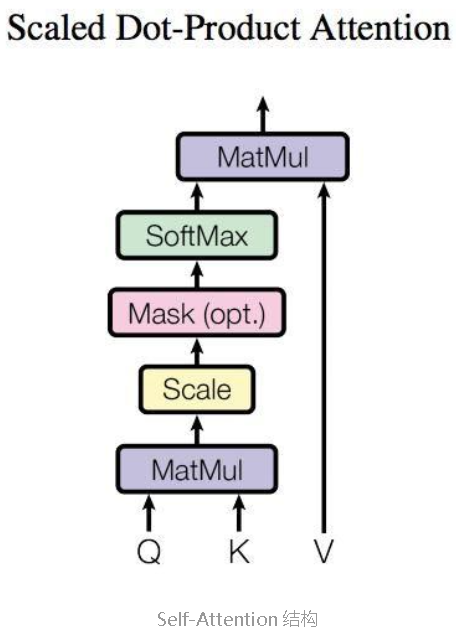
简而言之,已知
得到
最终结果生成过程:
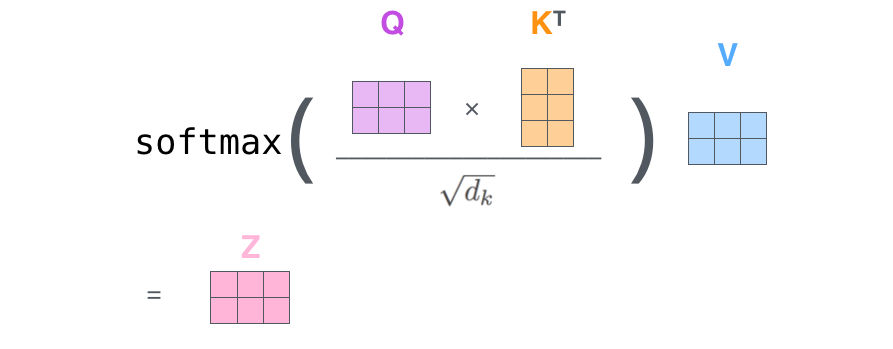
其中,
需要注意的是,在上述Self-Attention的计算过程中,通常基于mini-batch来进行计算,也就是一次计算多个句子。而一个mini-batch是由多个不等长的句子组成的,我们需要按照mini-batch中最大的句长对剩余的句子进行补齐,比如使用P作为填充字符,这个过程叫做padding。
对
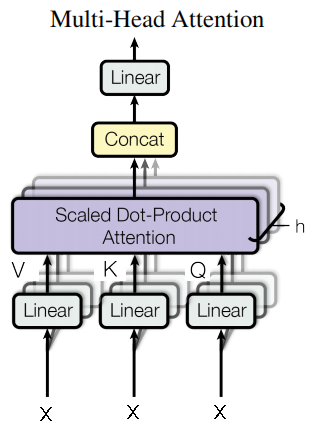
Multi-head Attention
多个Self-Attention的组合,即定义多组
Multi-Head Attention架构图如下:
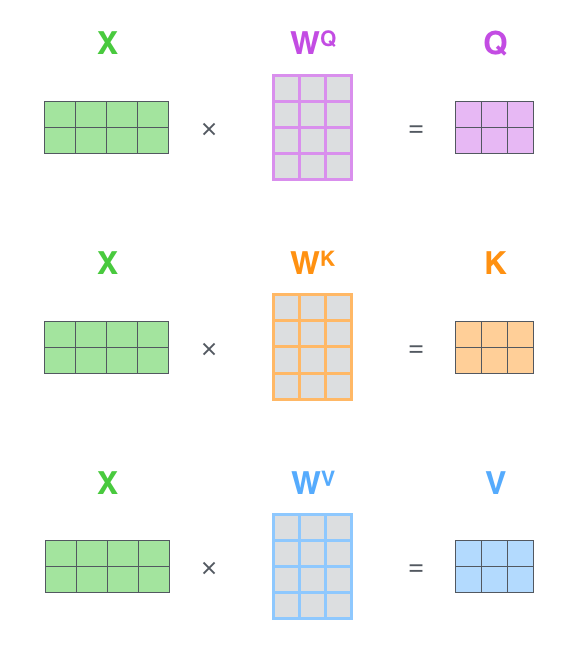
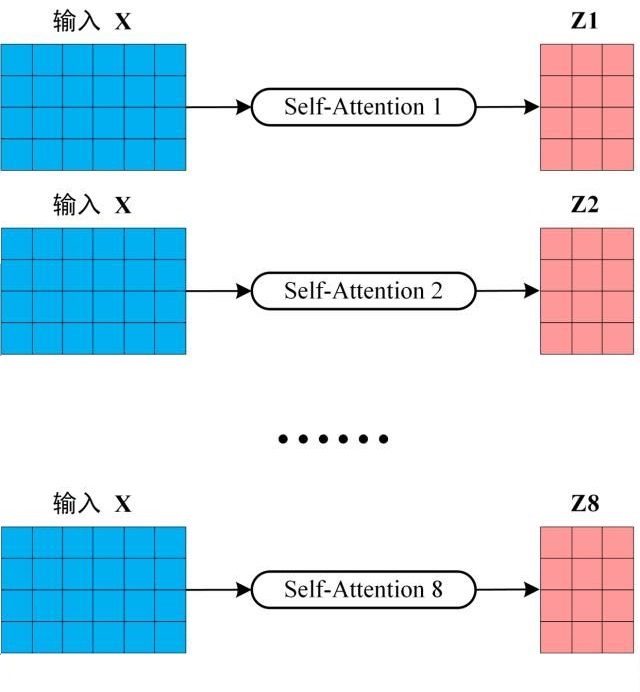
首先将输入
然后,将8 个输出矩阵
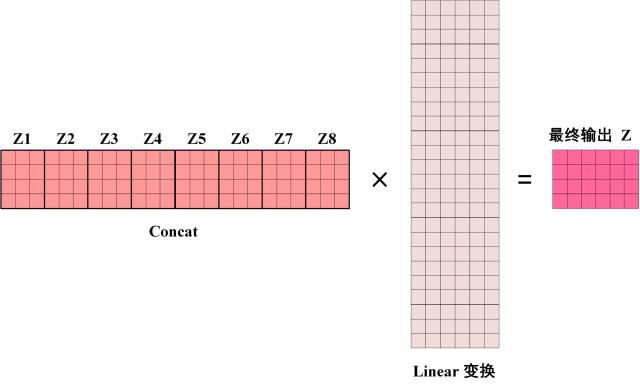
可以看到 Multi-Head Attention 输出的矩阵
add
残差连接。
norm
对
其过程如下图所示,其中,

线性层
Feed Forward
两层的线性变换,第一层使用ReLU作为激活函数,第二层不使用激活函数。对应公式如下:
线性变换后,再经过残差连接和Layer Norm处理,得到最终的输出,且维度与输入
add
对线性变化的结果进行残差连接。
norm
对
Encoder block总结
通过上面描述的 Multi-Head Attention,、Feed Forward、 Add & Norm 操作可以构造出一个 Encoder block。Encoder block 接收输入矩阵
第一个 Encoder block 的输入为句子单词的表示向量矩阵,后续 Encoder block 的输入是前一个 Encoder block 的输出,最后一个 Encoder block 输出的矩阵就是编码信息矩阵
Decoder
该结构的主要功能点如下:
包含两个Multi-Head Attention
- Masked Multi-Head Attention
- Multi-Head Attention:
最后的softmax层计算预测概率
输入
目标序列的前序序列,后续简称dec input。
Output Embedding
对dec_input进行word2vec词向量编码,后续简称
Positional Encoding
同Encoder的Positional Encoding,后续简称
输入整合
shape为[batch_size, tgt_len, d_model]。
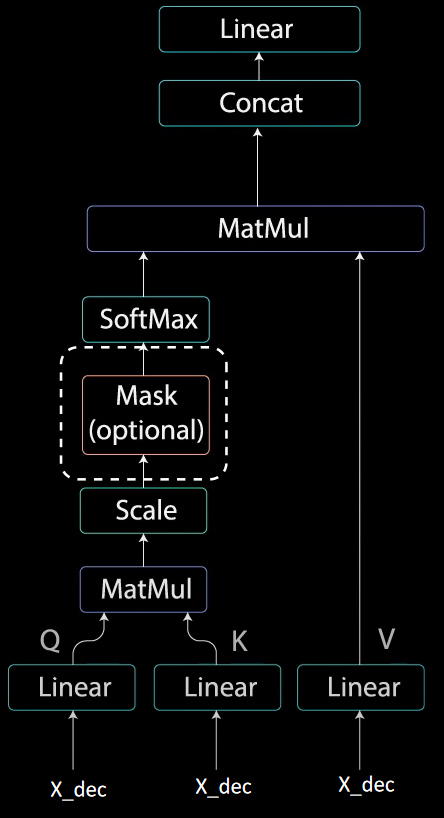
Masked Attention
Masked Multi-Head Attention
对
Masked Multi-Head Attention整体流程图如下:
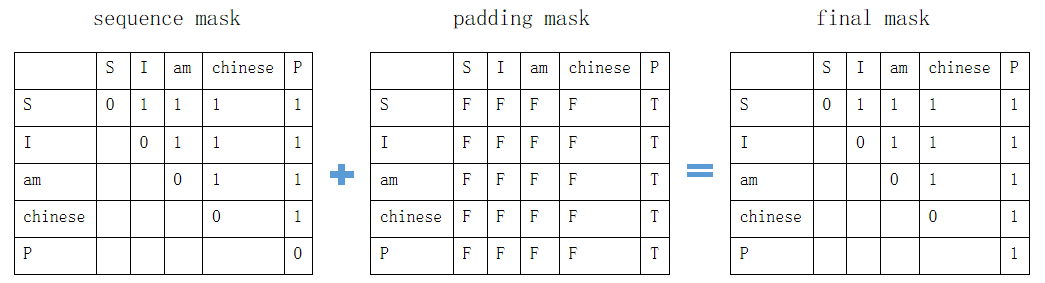
mask过程如下,在final mask中,数值为1的将被替换为-inf:
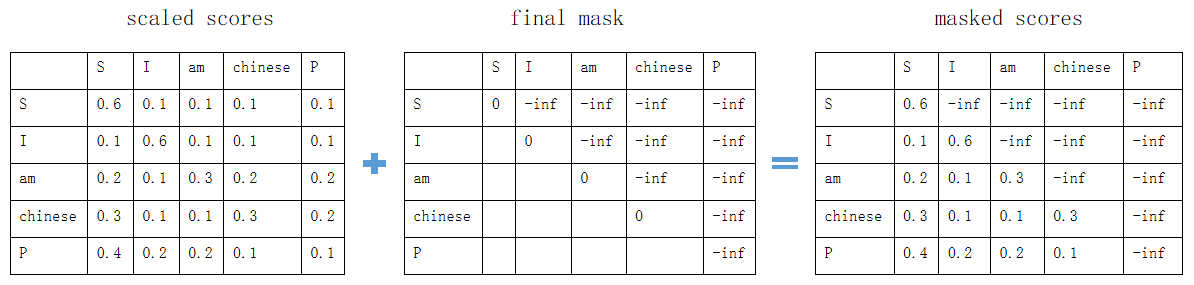
使用final mask矩阵,对scaled scores矩阵进行mask:
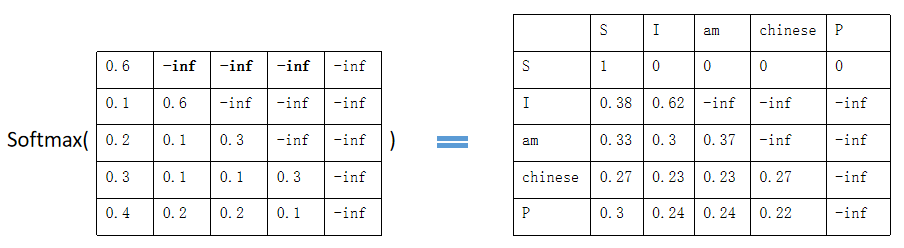
基于masked scores进行softmax计算,可以将-inf变为0,得到的矩阵即为每个词之间的权重:
最后,对权重矩阵再进行scale,然后与
将输出结果做残差连接及Layer Normlization后,输入到下一步的Multi-Head Attention。
将该步的结果记为
Multi-Head Attention
Encoder的输出结果(矩阵
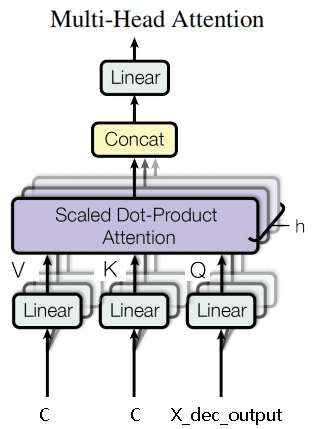
该步
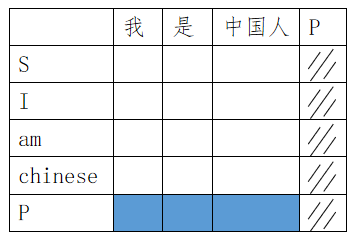
最后一行蓝色部分未进行padding mask,但是对最后一列必须进行padding mask。
线性层
Feed Forward、add、norm与前文类似,不再赘述。
最后输出的结果,其shape为[batch_size, tgt_len, d_model],与最初的输入
结果输出
Linear
将Decoder的输出,通过Linear操作映射为[batch_size, tgt_len, tgt_vocab_size]的矩阵。
Softmax
通过Softmax计算出概率,然后
Loss
使用交叉熵损失函数计算loss。
预测
dec_input的第一个字符为S,然后逐字预测,将概率最大的词加入到dec_input,如果该词是E,则结束。
xxxxxxxxxx171def greedy_decoder(model, enc_input, start_symbol):2 # 根据enc_input获取enc_outputs3 enc_outputs, enc_self_attns = model.encoder(enc_input)4 dec_input = torch.zeros(1, 0).type_as(enc_input.data)5 terminal = False6 next_symbol = start_symbol7 while not terminal: 8 # 将上一步预测的最大概率的词,作为dec_input9 dec_input=torch.cat([dec_input,torch.tensor([[next_symbol]],dtype=enc_input.dtype)],-1)10 dec_outputs, _, _ = model.decoder(dec_input, enc_input, enc_outputs)11 projected = model.projection(dec_outputs)12 prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1]13 next_word = prob.data[-1]14 next_symbol = next_word15 if next_symbol == word2idx["E"]:16 terminal = True17 return dec_input
参考文档
- The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time. (jalammar.github.io)
- wmathor/nlp-tutorial: Natural Language Processing Tutorial for Deep Learning Researchers (github.com)
- Transformer详解 - mathor (wmathor.com)
- Transformer的PyTorch实现 - mathor (wmathor.com)
- In-layer normalization techniques for training very deep neural networks | AI Summer (theaisummer.com)
- Transformer模型详解(图解最完整版) - 知乎 (zhihu.com)
- BERT大火却不懂Transformer?读这一篇就够了 - 知乎 (zhihu.com)
- Transformer论文逐段精读【论文精读】哔哩哔哩bilibili
- Transformer从零详细解读(可能是你见过最通俗易懂的讲解)哔哩哔哩bilibili
- Transformer代码(源码)从零解读(Pytorch版本)哔哩哔哩bilibili
- Transformer的PyTorch实现哔哩哔哩bilibili
- 从语言模型到Seq2Seq:Transformer如戏,全靠Mask - 科学空间|Scientific Spaces