LDA2022-10-27
LDA简介
潜在狄利克雷分配(latent Dirichlet allocation,LDA),是基于贝叶斯学习的话题模型。
LDA模型是文本集合的生成概率模型。假设每个文本由话题的一个多项分布表示,每个话题由单词的一个多项分布表示。特别假设文本的话题分布的先验分布是狄利克雷分布,话题的单词分布的先验分布也是狄利克雷分布。
LDA的文本集合的生成过程如下:
- 随机生成一个文本的话题分布;
- 在该文本的每个位置,依据该文本的话题分布随机生成一个话题,然后在该位置依据该话题的单词分布随机生成一个单词,直到文本的最后一个位置,生成整个文本;
- 重复以上步骤,生成所有文本。
LDA模型是含有隐变量的概率图模型:
隐变量:
- 每个文本的话题分布
- 每个话题的单词分布
- 文本的每个位置的话题
观测变量:
LDA模型的学习通常使用吉布斯采样或变分EM算法,前者是蒙特卡罗法,后者是近似算法。
狄利克雷分布
分布定义
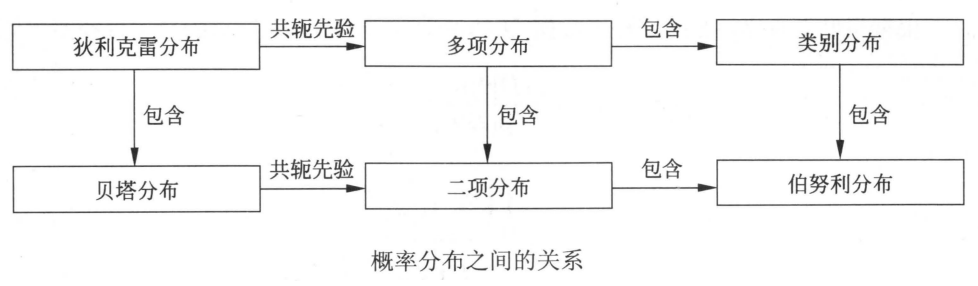
概率分布的关系如上图所示,各概率分布定义如下所述。
多项分布
假设重复进行次独立随机试验,每次试验可能出现的结果有种,第种结果出现的概率为,第种结果出现的次数为。如果用随机变量表示试验所有可能结果的次数,其中表示第种结果出现的次数,那么随机变量服从多项分布。
。
当试验的次数为1时,多项分布变成类别分布,类别分布表示试验可能出现的种结果的概率。
狄利克雷分布
狄利克雷分布是一种多元连续随机变量的概率分布,是贝塔分布的扩展。在贝叶斯学习中,狄利克雷分布常作为多项分布的先验分布进行使用。
。
式中是伽马函数,定义为:
该函数具有如下性质:
令:
则狄利克雷分布的密度函数可以写成:
由概率密度函数性质得:
因此:
上式为多元贝塔函数的积分表示。
二项分布
二项分布是多项分布的特殊情况,是指如下概率分布:是离散随机变量,取值为,其概率质量函数为:
当为1时,二项分布变成伯努利分布或0-1分布。
贝塔分布
贝塔分布是狄利克雷分布的特殊情况,是指如下概率分布:是随机变量,取值范围是,其概率密度函数为:
是贝塔函数,定义为:
当是自然数时,
共轭先验
狄利克雷重要性质:(1)狄利克雷分布属于指数族分布;(2)狄利克雷分布是多项分布的共轭先验。
如果后验分布与先验分布属于同类,则先验分布与后验分布称为共轭分布,先验分布称为共轭先验。
如果多线分布的先验分布是狄利克雷分布,则其后验分布也是狄利克雷分布,两者构成共轭先验。作为先验分布的狄利克雷分布的参数又称为超参数。使用共轭分布的好处是便于从先验分布计算后验分布。
设是由个元素组成的集合。随机变量服从上的多项分布,,其中和是参数。参数为从中重复独立抽取样本的次数,为样本中出现的次数,参数为出现的概率。
将样本数据表示为,目标是计算在样本数据给定条件下参数的后验概率。
对于给定的样本数据,似然函数是:
假设随机变量服从狄利克雷分布,其中为参数,则的先验分布为:
根据贝叶斯规则,在给定样本数据和参数条件下,的后验概率分布是:
可以看出,先验分布和后验分布都是狄利克雷分布,两者有不同的参数,所以狄利克雷分布是多项分布的共轭先验。狄利克雷后验分布的参数等于狄利克雷先验分布参数加上多项分布的观测计数。
备注:关于上述的公式推导,补充个人的解释
等式左边可以理解为给定超参数,先生成参数,然后生成数据集,可以理解为,参考马尔可夫性,可得。
LDA模型
基本想法
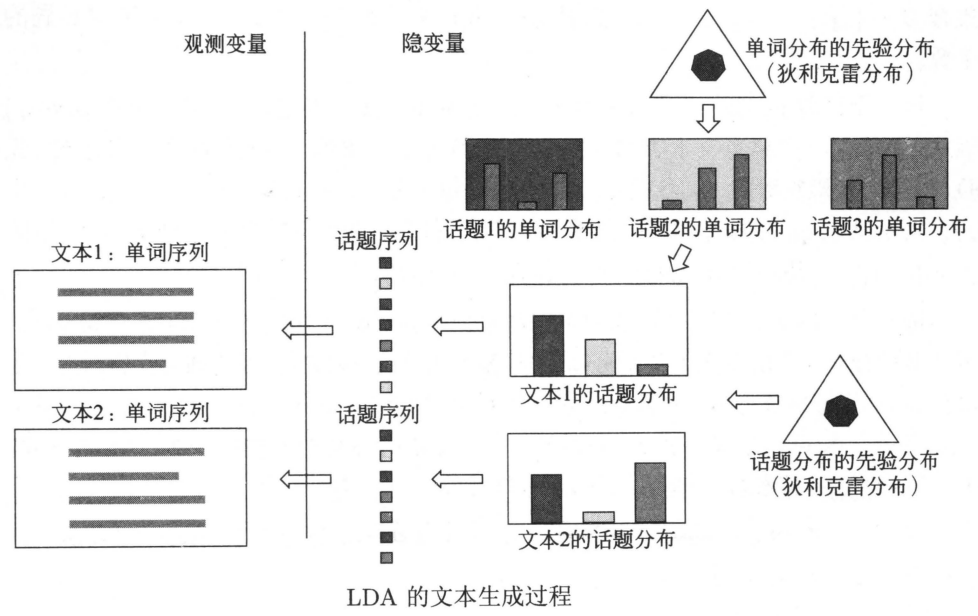
上图为LDA的文本生成过程:
- 基于单词分布的先验分布(狄利克雷分布)生成多个单词分布,即决定多个话题内容
- 基于话题分布的先验分布(狄利克雷分布)生成多个话题分布,即决定多个文本内容
- 对每个文本,基于该文本的话题分布生成话题序列,针对每一个话题,基于话题的单词分布生成单词,整体构成一个单词序列,即生成文本,重复这个过程生成所有文本
LDA是概率图模型,其特点是以狄利克雷分布为多项分布的先验分布,学习就是给定文本集合,通过后验概率分布的估计,推断模型的所有参数。利用LDA进行话题分析,就是对给定文本集合,学习到每个文本的话题分布,以及每个话题的单词分布。
LDA与PLSA的异同:
相同点
不同点
- 对文本生成过程假设不同:LDA使用狄利克雷分布作为先验分布,而PLSA不使用先验分布(或假设先验分布是均匀分布);
- 学习过程不同:LDA基于贝叶斯学习,PLSA基于极大似然估计。
模型定义
模型要素
LDA使用三个集合:
单词集合
,其中,是第个单词,,是单词的个数。
文本集合
,其中,是第个文本,,是文本的个数。
文本是一个单词序列,,其中是文本的第个单词,是文本中单词的个数。
话题集合
,其中,是第个话题,,是话题的个数。
对每个话题生成单词:
- 话题由一个单词的条件概率分布决定,
- 分布服从多项分布(严格意义上讲是类别分布,每次只做1次试验),其参数为
- 参数服从狄利克雷分布(先验分布),其超参数为
- 参数是一个维向量,,其中,表示话题生成单词的概率
- 所有话题的参数向量构成一个的矩阵
- 超参数也是一个维向量,
总结:
对每个文本生成话题:
文本由一个话题的条件概率分布决定,
分布服从多项分布(严格意义上的类别分布),其参数为
参数服从狄利克雷分布(先验分布),其超参数为
参数是一个维向量,,其中,表示文本生成话题的概率
所有文本的参数向量构成一个的矩阵
超参数也是一个维向量,
总结:
分布示例(以文本生成话题为例):
狄利克雷分布 - 初始化参数
根据狄利克雷分布,生成多项分布的参数
根据多项分布,生成话题:
生成过程
给定单词集合,文本集合,话题集合,狄利克雷分布的超参数和。
(1)生成话题的单词分布
随机生成个话题的单词分布。按照狄利克雷分布随机生成一个参数向量,,将作为话题的单词分布(多项分布)的参数,,。
(2)生成文本的话题分布
随机生成个文本的话题分布。按照狄利克雷分布随机生成一个参数向量,,将作为文本的话题分布(多项分布)的参数,,。
(3)生成文本的单词序列
文本的单词的生成过程如下:
(3-1)生成话题:按照多项分布随机生成一个话题,
(3-2)生成单词:按照多项分布随机生成一个单词,
伪代码
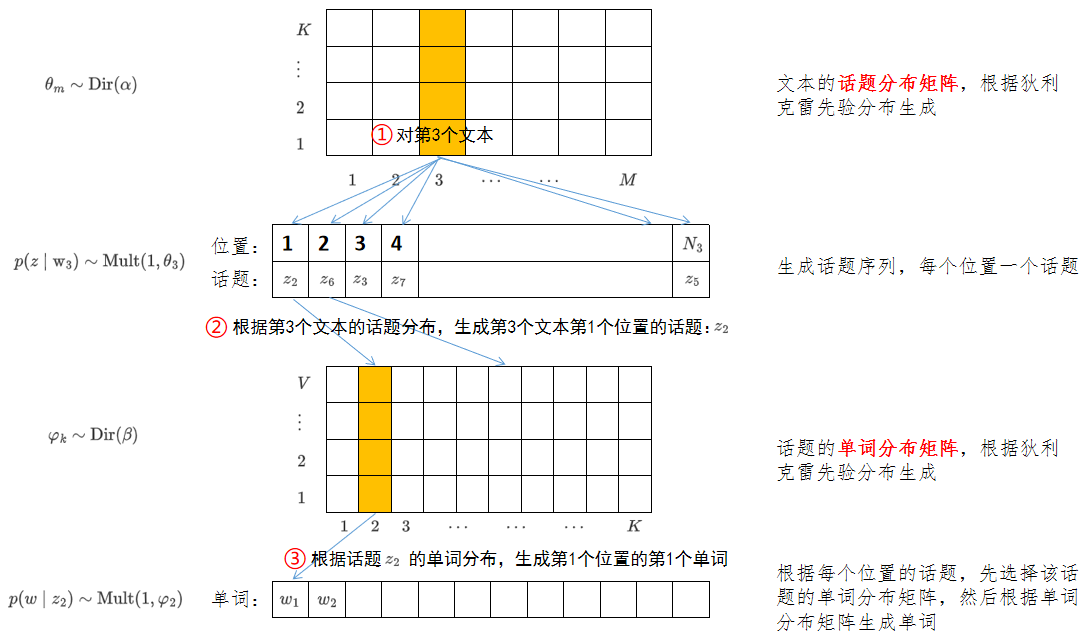
初始化话题分布的超参数,长度为,和话题数一样
生成话题分布的参数,其长度为,共个,一个文档对应一个话题分布
假设有三个话题,对第一个文档:,则可以按该分布生成话题序列:
初始化单词分布的超参数,长度为,和单词数一样
生成单词分布的参数,其长度为,共个,一个话题对应一个单词分布
假设第一个文档有两个单词,因为一共有三个话题,使用生成三个,如下:
生成文本
以第一个文档为例,该文档有两个单词,假设:
概率图模型
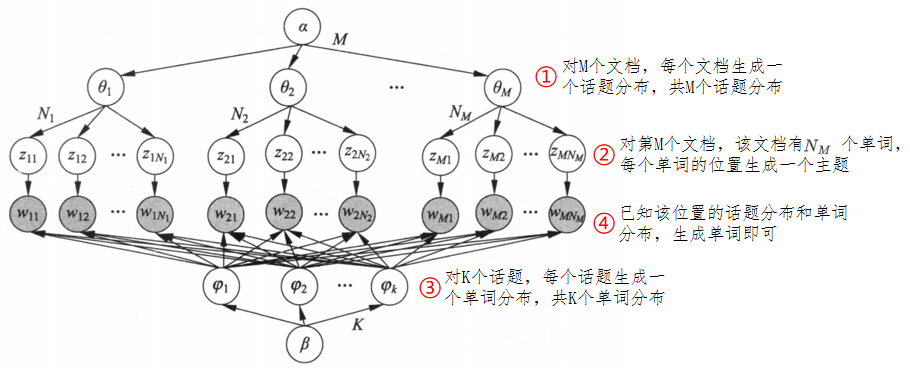
LDA本质是概率图模型。下图为LDA作为概率图模型的板块表示,解释如下:
- 实心圆:观测变量
- 空心圆:隐变量
- 有向边:概率依存关系
- 矩形:表示重复,矩形内的数字表示重复的次数。
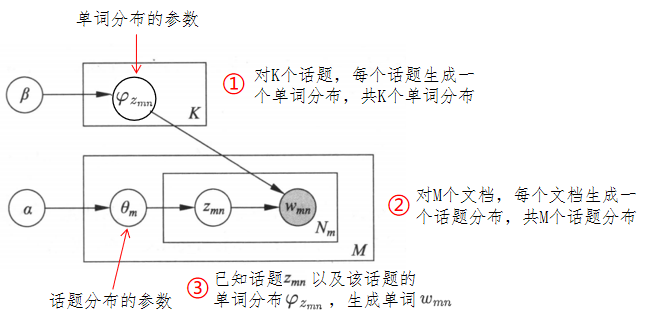
板块表示的优点是简洁,板块表示展开之后,称为普通的有向图表示(如下图所示)。有向图中结点表示随机变量,有向边表示概率依存关系。
随机变量序列的可交换性
如果随机变量的联合概率分布对随机变量的排列不变,则称该随机变量序列是可交换的。即:
一个无限的随机变量序列是无限可交换的,是指它的任意一个有限子序列都是可交换的。
如果一个随机变量序列是独立同分布的,那么它们是无限可交换的。反之不然。
根据De Finetti定理,任意一个无限可交换的随机变量序列对一个随机参数是条件独立同分布的。即:
LDA假设文本由无限可交换的话题序列组成。由De Finetti定理可知,实际是假设文本中的话题对一个随机参数是条件独立同分布的。所以,在参数给定的条件下,文本中的话题顺序可以忽略。作为对比,概率潜在语义模型假设文本中的话题是独立同分布的,文本中的话题的顺序也可以忽略。
概率公式
LDA模型整体是由观测变量和隐变量组成的联合概率分布,可以表示为:
其中,各符号含义如下:
- :所有文本中的单词序列
- 隐变量:所有文本中的话题序列
- 隐变量:所有文本的话题分布的参数
- 隐变量:所有话题的单词分布的参数
- 和 :超参数
- :给定 条件下第个话题的单词分布的参数的生成概率
- :给定条件下第个文本的话题分布的参数的生成概率
- :第个文本的话题分布给定条件下文本的第个位置的话题的生成概率
- :在第文本的第个位置的话题及所有话题的单词分布的参数给定条件下第个文本的第个位置的单词的生成概率
第个文本的联合概率分布可以表示为:
LDA模型的联合分布含有隐变量,对隐变量进行积分得到边缘分布。
参数和给定条件下第个文本的生成概率是(第二个公式是原书20.17,第一个公式是补充):
超参数和给定条件下第个文本的生成概率是:
超参数和给定条件下所有文本的生成概率是:
LDA的吉布斯抽样算法
基本想法
已知:文本序列的集合,其中是第个文本,;
超参数和。
目标是要推断:
(1) 话题序列的集合的后验概率分布,其中是第个文本的话题序列,;
(2) 参数,其中是文本的话题分布的参数;
(3) 参数,其中是话题的单词分布的参数。
概括:要对联合概率分布进行估计,其中是观测变量,而是隐变量。
LDA模型的学习可以采用收缩的吉布斯抽样方法,其基本想法是:
- 对隐变量和进行积分,得到边缘概率分布,其中是可观测的,是不可观测;
- 对后验概率分布进行吉布斯抽样,得到分布的样本集合;
- 利用步骤2的样本集合对参数和进行估计,最终得到LDA模型的所有参数估计。
算法的主要部分
根据上面的分析,问题转化为对后验概率分布的吉布斯抽样。该分布表示在所有文本的单词序列给定条件下所有可能话题序列的条件概率。例如,假设有10个文本,3个话题,那么表示已知10个文本的内容,3个话题各种情况的概率是多少。
抽样分布的表达式
首先有关系:
因为变量已知,分母相同,可以不予考虑。
根据及,联合分布的表达式可以进一步分解为:
接下来,对两个因子分别处理:
首先:
于是:
首先:
于是:
由上式推导可得:
因此,收缩的吉布斯抽样分布的公式为:
满条件分布的表达式
分布的满条件分布可以写成:
上式是在所有文本单词序列、其它位置话题序列给定条件下第个位置的话题的条件概率分布。
由上式可得:
算法的后处理
通过吉布斯抽样得到的分布的样本,可以得到变量的分配值,也可以估计变量和。
参数的估计
根据LDA模型的定义,后验概率满足:
于是得到参数的估计式:
参数的估计
后验概率满足:
于是得到参数的估计式:
吉布斯抽样具体算法
对给定的所有文本的的单词序列,每个位置上随机指派一个话题,整体构成所有文本的话题序列。然后循环执行以下操作:
在每一个位置上计算在该位置上的话题的满条件概率分布,然后进行随机抽样,得到该位置的新的话题,分配给这个位置。
上述条件概率分布由两个因子组成:
- 话题生成该位置的单词的概率
- 该位置的文本生成话题的概率
整体准备两个计数矩阵:话题-单词矩阵和文本-话题矩阵。在每一个位置,对两个矩阵中该位置的已有话题的计数减1,计算满条件概率分布,然后进行抽样,得到该位置的新话题,之后对两个矩阵中该位置的新话题的计数加1。计算移到下一个位置。
在燃烧期之后得到的所有文本的话题序列就是条件概率分布的样本。
变分EM算法
变分推理
本质上讲,是一种退而求其次的办法。
变分推理的基本想法如下:假如模型是联合概率分布,其中是观测变量(已有数据,如文档),是隐变量,包括参数。目标是学习模型的后验概率分布,用模型进行概率推理。
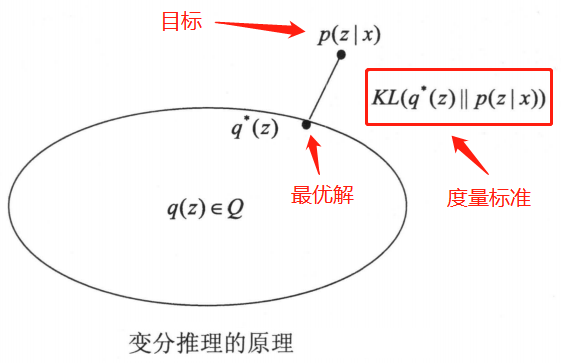
但是,一般情况下是复杂的分布,直接估计分布的参数很困难。所以考虑用概率分布近似条件概率分布,用散度计算两者的相似度,称为变分分布。
如果能找到有在散度意义下最近的分布,则可以用该分布近似表示。
下图给出了与的关系。
散度可以写成以下形式:
因为散度大于等于零,当且仅当两个分布一致时为零。由此可知:
不等式右端是左端的下界,左端称为证据,右端称为证据下界,证据下界记作:
散度的最小化可以通过证据下界的最大化实现。因为目标是求使散度最小化,这时是常量,因此,变分推理变成求解证据下界最大化的问题。
变分推理也可以从另一个角度理解。目标是通过证据的最大化,估计联合概率分布。因为含有隐变量,直接对证据进行最大化比较困难,转而根据对证据下界进行最大化。
对变分分布要求是需要具有容易处理的形式,通常假设对的所有分量都是互相独立的(实际是条件独立于参数),即满足:
这时的变分分布称为平均场。
散度的最小化或证据下界最大化实际是在平均场的集合中,即满足独立假设的分布集合之中进行的。
总的来说,变分推理有以下几个步骤:
- 定义变分分布
- 推导其证据下界表达式
- 用最优化方法对证据下界进行优化,如坐标上升,得到最优分布,作为后验分布的近似。
变分EM算法
变分推理中,可以通过迭代的方法最大化证据下界,这时算法是算法的推广,称为变分算法。
假设模型是联合概率分布,其中是观测变量,是隐变量,是参数。目标是通过观测数据的概率(证据)的最大化,估计模型的参数。使用变分推理,导入平均场,定义证据下界:
通过迭代,分别以和为变量对证据下界进行最大化,就得到变分算法。如下所述:
根据变分推理,观测数据的概率和证据下界满足:
变分算法的迭代过程中,以下关系成立:
公式解释如下:
- :基于步计算和变分推理原理
- :基于步计算
- :基于变分推理原理
说明每次迭代都能保证观测数据的概率不递减。因此,变分算法一定收敛,但可能收敛到局部最优。
算法推导
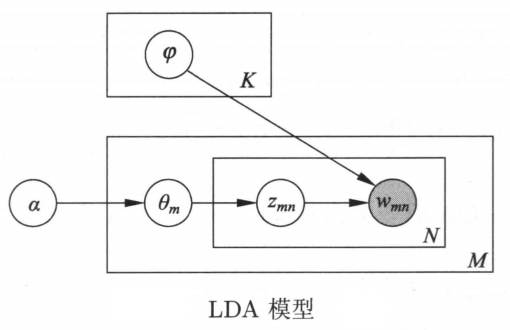
上图是LDA模型的简化版。将变分算法应用到LDA模型,首先定义具体的变分分布,推导证据下界大表达式,接着推导变分分布的参数和LDA模型的参数的估计式,最后给出LDA模型的变分算法。
证据下界的定义
为简单起见,一次只考虑一个文本,记作。文本的单词序列,对应的话题序列,以及话题分布。
随机变量、和的联合分布是:
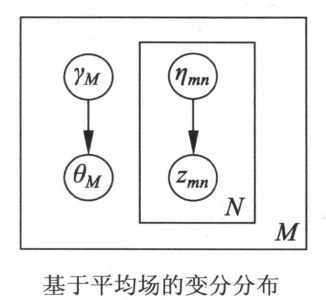
定义基于平均场的变分分布:
目标是求散度意义下最相近的变分分布,以近似LDA模型的后验分布。
下图是变分分布的板块表示。LDA模型中的隐变量和之间存在依存关系,变分分布中这些依存关系被去掉,变量和条件独立。
由此得到一个文本的证据下界:
其中,数学期望是对分布定义的,为了方便写作。
所有文本的证据下界为:
为求证据下界的最大化,首先写出证据下界的表达式。为此展开单个文本的证据下界式:
根据变分参数和,模型参数和继续展开,并将展开式的每一项写成一行:
式中是对数伽马函数的导数,即:
第一项推导,求,是关于分布的数学期望。
其中,,所以,利用狄利克雷分布的性质:
有:
故得:
第二项推导,求,是关于分布的数学期望。
第三项推导,求,是关于分布的数学期望。
第四项推导,求,是关于分布的数学期望。由于,可以得到:
第五项推导,求,是关于分布的数学期望。
变分参数和的估计
首先通过证据下界最优化估计参数。
表示第个位置的单词是由第个话题生成的概率。考虑到关于的最大化,满足约束条件。包含的约束最优化问题拉格朗日函数为:
对求偏导数,可得:
令偏导数为零,得到参数的估计值:
接着,通过证据下界最优化估计参数。是第个话题的狄利克雷分布参数。考虑关于的最优化:
简化为:
对求偏导数可得:
令偏导数为零,求解得到参数的估计值:
据此,得到由坐标上升算法估计变分参数的方法,具体算法如下:
模型参数和的估计
给定一个文本集合,模型参数估计对所有文本同时进行。
首先,通过证据下界的最大化估计。表示第个话题生成单词集合第个单词的概率。将扩展到所有文本,并考虑关于的最大化。满足个约束条件:
约束最优化问题的拉格朗日函数为:
对求偏导数并令其为零,归一化求解,得到参数的估计值:
接着,通过证据下界的最大化估计参数。表示第个话题的狄利克雷分布参数。将扩展到所有文本,并考虑关于的最大化:
对求偏导数得:
再对求偏导数得:
和分别是函数对变量的梯度和矩阵。应用牛顿法求该函数的最大化。用以下公式迭代,得到参数的估计值。
据此,得到估计参数的算法。
算法总结
根据上面的推导给出简化LDA的变分算法。
参考文档
- 李航 《统计学习方法》
- 第二十课 潜在狄利克雷分配 (julyedu.com)
- 《统计学习方法》啃书手册|第20章 潜在狄利克雷分配 - 知乎 (zhihu.com)
- [统计学习] 2 LDA (潜在狄利克雷分配) 算法过程的直观理解 - 知乎 (zhihu.com)