PLSA2022-10-12
前置知识
概率公式
加法公式
乘法公式
贝叶斯公式
独立随机变量的性质
如果两个随机变量和独立,那么:
根据乘法公式:
因此:
PLSA简介
概率潜在语义分析(probabilistic latent semantic analysis,PLSA),是一种利用概率生成模型对文本集合进行话题分析的无监督学习方法。模型的特点是使用隐变量表示话题,模型的过程为文本生成话题,话题生成单词,从而得到单词-文本共现数据。假设每个文本由一个话题分布决定,每个话题由一个单词分布决定。
PLSA模型
PLSA有生成模型,以及等价的共现模型。
生成模型
假设有如下集合:
单词集合
,其中,为单词个数
文本集合
,其中,为文本个数
话题集合
,其中,为话题个数
随机变量取值于单词集合,随机变量取值于文本集合,随机变量取值于话题集合。定义如下概率分布(都是多项式分布):
- :生成文本的概率
- :文本生成话题的概率
- :话题生成单词的概率
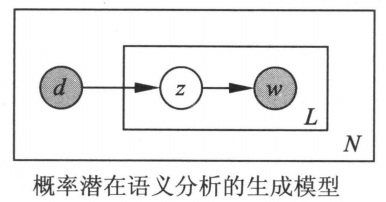
生成模型通过以下步骤生成文本-单词共现数据:
- 依据概率分布,从文本集合中随机选取一个文本,共生成个文本。针对每个文本,执行以下操作:
- 在文本给定条件下,依据概率条件分布,从话题集合随机选取一个话题,共生成个话题,其中是文本长度;
- 在话题给定条件下,依据概率条件分布,从单词集合中随机选取一个单词。
在生成模型中,单词变量与文本变量是观测变量,话题变量是隐变量。该模型生成的是单词-话题-文本三元组,但观测到的是单词-文本二元组的集合。观测数据由单词-文本矩阵进行形式,行表示单词,列表示文本,数值表示单词-文本对的出现次数。
从数据的生成过程可以推出,单词-文本共现数据的生成概率为所有单词-文本对的生成概率的乘积:
生成模型假设在话题给定条件下,单词与文本条件独立,即:
根据概率公式,每个单词-文本对的生成概率由以下公式决定:
上式即为生成模型的定义。
生成模型属于概率有向图模型,可以用有向图表示。如下图所示,实心圆表示观测变量,空心圆表示隐变量,箭头表示概率依存关系,方框表示多次重复,方框内的数字表示重复的次数。
共现模型
文本-单词共现数据的生成概率为所有单词-文本对的生成概率的乘积:
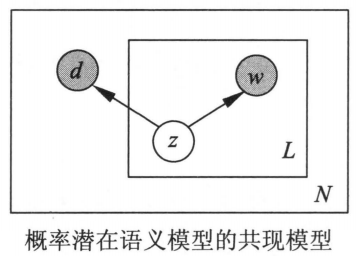
共现模型假设在话题给定条件下,单词与文本条件独立,即:
根据概率公式,每个单词-文本对的概率由以下公式决定:
上式即为共现模型的定义。
下图所示为共现模型。文本变量和单词变量为观测变量,话题变量为隐变量
总结
生成模型刻画文本-单词共现数据生成的过程,共现模型描述文本-单词共现数据拥有的模式。生成模型公式中单词变量与文本变量是非对称的,而共现模型公式中的单词变量与文本变量是对称的。因此,前者称为非对称模型,后者称为对称模型。
PLSA的学习方法
生成模型
定义对数似然函数
优化目标是对数似然函数最大化,该函数定义如下:
因 和 都为常数,因此,将对数似然函数简化为:
E步:定义Q函数
根据Jesson不等式:
定义概率分布函数,对于对数似然函数:
因为为常数,因此上式可简化为:
定义函数为:
函数为对数似然函数的下界,将对的极大化问题,转为对的极大化问题。
根据概率公式,对化简为:
所以,函数可以化简为:
和为变量,即待求解参数。
M步:极大化Q函数
极大化函数是一个带约束的最优化问题。因为变量和为概率分布,因此:
应用拉格朗日乘子法,引入拉格朗日乘子和,定义拉格朗日函数:
将拉格朗日函数分别对和求偏导,并令其为0,得:
解方程组,得到M步的参数估计公式:
总结
概率潜在语义模型(PLSA)参数估计的算法:
输入:单词集合,文本集合,话题集合,共现数据。
输出:和
步骤:
(1)设置参数和的初始值
(2)迭代执行E步和M步,直到收敛为止。
E步:
M步:
共现模型
暂略。
参考文档
- 李航 《统计学习方法》
- 【学习笔记】pLSA算法原理手写推导 - 知乎 (zhihu.com)
- PLSA的EM算法求解6哔哩哔哩_bilibili
- (143条消息) 李航老师《统计学习方法》第二版第十八章概率潜在语义分析课后习题答案_六七~的博客-CSDN博客