BERT简介
BERT全称为Bidirectional Encoder Representation from Transformer,是 Google 以无监督的方式利用大量无标注文本训练的语言模型,其编码架构为 Transformer 中的 Encoder(BERT=Encoder of Transformer)。
Bidirectional
传统语言模型为单向结构,即
Encoder
BERT是仅仅采用了Transformer中的Encoder部分,Base BERT采用了12层Encoder。
预训练
BERT采用了两种任务对文本进行无监督的预训练,MLM(Masked Language Model)和 NSP(Next Sentence Prediction)。
微调
- 输入序列,输出分类:如情感分析、文本分类。
- 输入序列,输出序列:如序列标注。
- 输入两个句子,输出分类:如自然语言推理
- QA问答
BERT预训练模型
总体架构
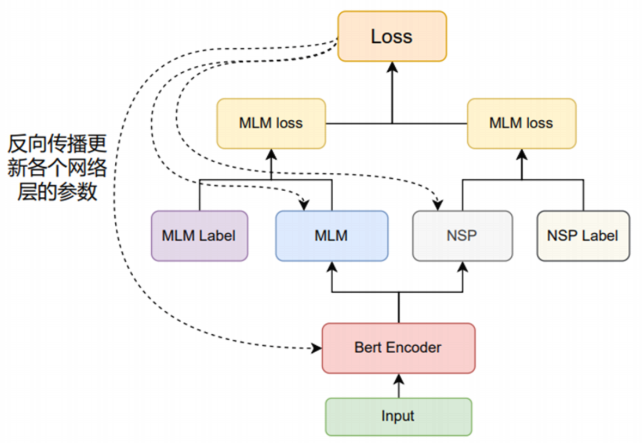
对原始输入Input,通过Bert Encoder编码后,进行MLM任务和NSP任务,产生一个联合训练的损失函数,在迭代训练过程中更新整个模型中的参数。
输入
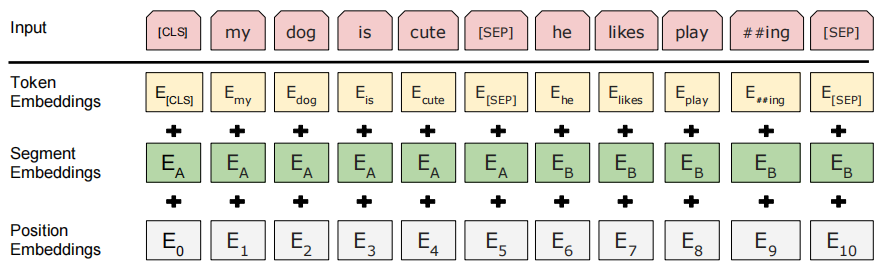
原始句子
['my dog is cute', 'he likes playing']
分词处理 -> Input
['CLS', 'my', 'dog', 'is', 'cute', 'SEP', 'he', 'likes', 'play', '##ing', 'SEP']
Embedding
Token Embeddings
Token级:对Input中的每个Token做Embedding。
Segment Embeddings
句子级:对每个句子做Embedding,例如Input中有两个句子,其编号为
Position EMbeddings
位置级:对Input中各token的位置进行Embedding。
最后,将三个Embedding相加,作为模型的输入。
Encoder编码
将Embedding的结果作为输入,使用Transformer Encoder进行处理,Bert Base使用12层Encoder,最后输出编码好的张量,其shape为:
预训练模型
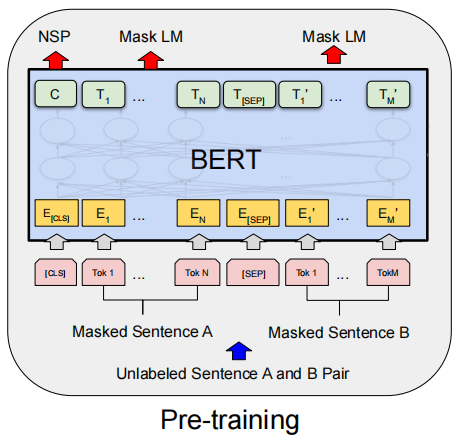
MLM任务
MLM(Masked Language Model):随机Mask若干单词完成训练集的构造,然后根据上下文来预测被遮挡的单词。
Mask过程:
- 对每一对句子,随机选择15%的token进行Mask。
- 对步骤1选择的15%的token,将其80%替换为'
',10%随机替换,10%保持不变。
MLM训练步骤:
输入:对Bert Encoder层的输出进行Mask操作,得到训练数据
模型:MLP
输出:预测结果,其shape为
NSP任务
NSP(Next Sentence Prediction):判断句子B是否为句子A的下一句。
通过采样构造训练集,采样时,以50%的概率将第二个句子随机替换为段落中的任意一个句子。
NSP训练步骤:
输入:Bert Encoder层'
'位置的向量,shape为 模型:MLP,默认是一个输出维度为2,激活函数为Softmax的全连接层。
输出:预测结果,其shape为
损失函数
MLM
MLM 是个多分类任务,损失函数是CrossEntropyLoss。
对于MLM任务,只计算'
'及随机替换的部分,其余部分不做损失。 NSP
NSP是个二分类的任务,损失函数是binary_cross_entropy。
Total Loss
Total_loss = MLM_loss + NSP_loss
BERT微调
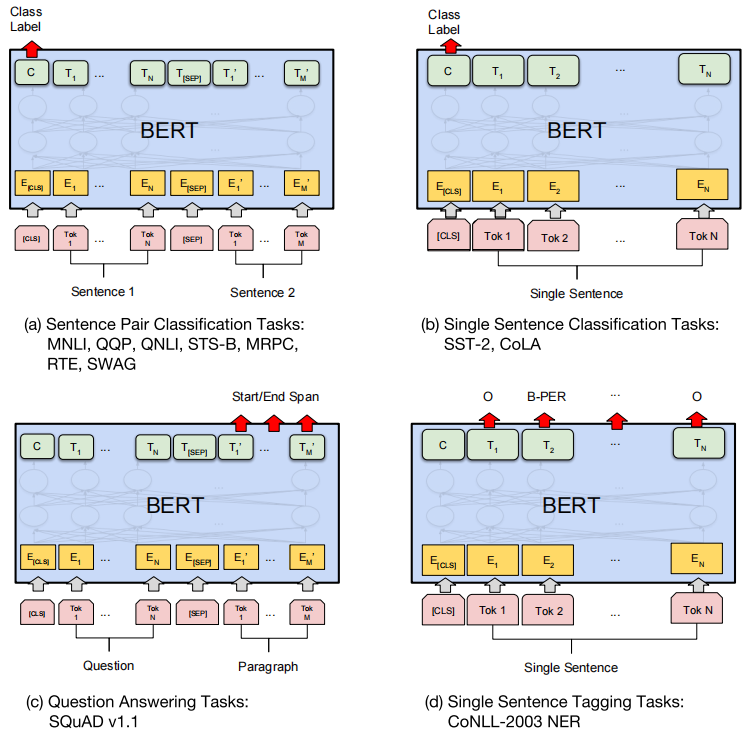
句子对分类
将'
'向量输入多分类的MLP。 单句子分类
将'
'向量输入多分类的MLP。 问答任务
对Paragraph句子的词向量,通过MLP进行三分类。
单句子标注任务
将Single Sentence部分的词向量通过MLP进行多分类。
参考文档
- 1810.04805.pdf (arxiv.org)
- 课程简介 - Hugging Face Course
- BERT 是如何分词的 - 知乎 (zhihu.com)
- BERT四大下游任务 - 知乎 (zhihu.com)